Hugging Face轻量化框架Candle实战|基于Rust,比PyTorch配置简单
导语
PyTorch很好,但配置起来太复杂,不妨试试Hugging Face 推出的Candle,部署更简单,与PyTorchAPI相似,还可以节省至少90%的环境配置时间,5分钟就能构建RAG应用。
正文
搞大模型这么久,说实话,我不信还有人在部署模型时候,没被本地配置PyTorch环境搞崩溃过……
比如,我有一个同事,最近想配置PyTorch环境,跑个BERT模型,结果折腾了2天还在报版本冲突。
其实,本地跑跑模型最大的坑,根本不是理解Transformer,而是搞定PyTorch和CUDA的环境配置。
比如,我同事最近遇到的坑。包括但不限于以下:
CUDA版本和PyTorch版本不匹配,比如CUDA 11.8和PyTorch的CUDA 11.7冲突。
从transformers库中导入BertTokenizer时出错。
BertModel对象没有pooler属性。
此外,transformers 4.21版本移除了某些API,PyTorch 2.0改变了tensor的默认行为,CUDA 12.0和显卡驱动不兼容,模型文件格式也从pytorch_model.bin变成了safetensors。
不跑不知道,一跑吓一跳。
PyTorch的确很强大,生态丰富又功能全面,尤其适合做研究,但对开发者来说,这种环境配置太痛苦了。
那不妨试试huggingface推出的Candle框架,相比传统Python,不仅部署更简单,还能让你节省至少90%的环境配置时间。更重要的是,一次编译,到处运行,再也不用担心版本冲突。
接下来,我们将展示Candle项目如何在5分钟内构建一个原本需要半天才能配好环境的RAG应用,还能轻松加载各种Transformer模型。
01
为什么选择Rust Candle的ML框架 在探讨Rust Candel之前,我们先来理解几个基础概念:
什么是Rust? Rust 是一门能写出运行速度极快并且绝对不会犯某些低级错误的编程语言。在机器学习框架领域,Rust 解决了模型部署时的依赖和环境一致性问题。它可以将整个框架或模型推理引擎编译成一个无依赖的、跨平台的单一二进制文件,实现了开箱即用,极大简化了在服务器、边缘设备和裸金属环境中的部署流程。
什么是 Candle? Candle 是 Hugging Face 推出的一个用 Rust 编写的极简机器学习框架,其核心能力是一个核心张量计算库和一套工具。
设计理念
轻量化部署 - 创建小型二进制文件,适合无服务器环境以及需要高性能推理快速部署的生产环境,可以避免 PyTorch 等大型框架的开销 。并且与PyTorch API相似,可以降低迁移成本。
去 Python 化 - 从生产工作负载中移除 Python 依赖,消除 GIL 相关的性能问题。并且用编译器的安全检查替代了 C++ 后端的运行时风险。
Rust 生态优势 - 利用 Rust 的安全性、性能和生态系统,与 safetensors 和 tokenizers 等工具集成 。
框架架构
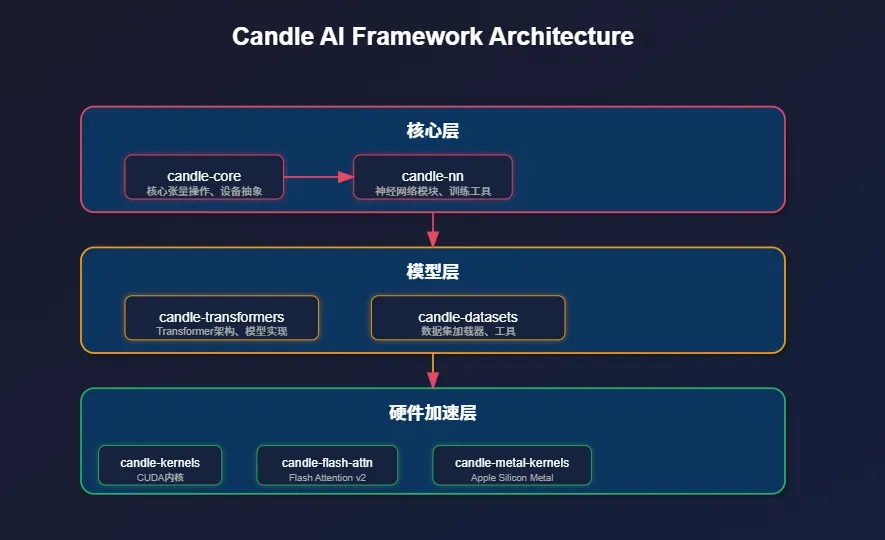
Candle采用三层模块化架构:
核心层:candle-core提供张量计算和设备抽象,candle-nn构建神经网络组件
模型层:candle-transformers实现Transformer架构,candle-datasets处理数据集
加速层:CUDA内核、Flash Attention v2、Apple Metal内核三大硬件加速
统一Device枚举抽象CPU/CUDA/Metal后端,提供PyTorch风格API,实现轻量化部署与去Python化。
 03-1.webp
03-1.webp
02
项目实战
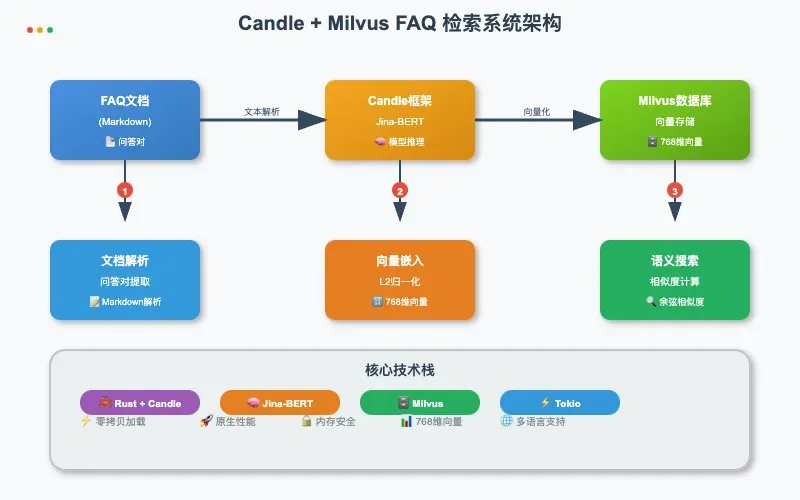
1. 项目架构说明
本实战基于Candle 框架和 Milvus 向量数据库FAQ检索系统。系统完全使用 Rust 生态实现,通过 Candle 框架加载 Jina-BERT 模型进行文本向量化,并使用 Milvus 进行高效的语义相似度搜索。
 03-2.webp
03-2.webp
2. 安装milvus
2.1 下载部署文件
wget https://github.com/milvus-io/milvus/releases/download/v2.5.12/milvus-standalone-docker-compose.yml -O docker-compose.yml
2.2 启动Milvus服务
docker-compose up -ddocker-compose ps -a
 03-3.webp
03-3.webp
3. 安装rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
3.1 检查安装是否成功
cargo --versionrustc --versionrustup --version
3.2 使用官方示例代码验证
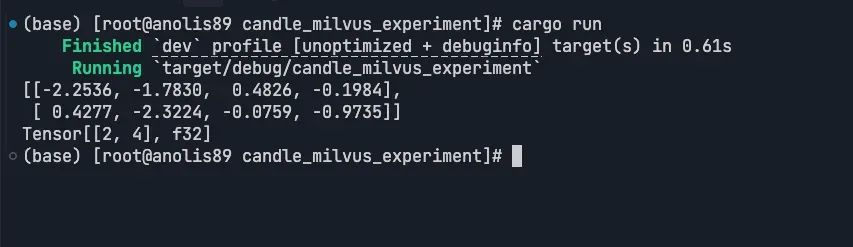
use candle_core::{Device, Tensor};fn main() -> Result<(), Box<dyn std::error::Error>> { let device = Device::Cpu; let a = Tensor::randn(0f32, 1., (2, 3), &device)?; let b = Tensor::randn(0f32, 1., (3, 4), &device)?; let c = a.matmul(&b)?; println!("{c}"); Ok(())}
3.3 运行代码
cargo run
 03-4.webp
03-4.webp
3.4 核心代码实现
主程序流程:
步骤1 : 初始化AI模型和分词器
步骤2 : 连接Milvus数据库,创建存储集合
步骤3 : 加载FAQ文档,解析问答对
步骤4 : 批量处理:文档 → 向量化 → 存储到数据库
步骤5 : 验证存储结果,输出统计信息
3.5 新建项目
mkdir candle_milvus_experiment#[cfg(feature = "mkl")]extern crate intel_mkl_src;#[cfg(feature = "accelerate")]extern crate accelerate_src;use candle_transformers::models::jina_bert::{BertModel, Config};use anyhow::Error as E;use candle::{DType, Device, Module, Tensor};use candle_nn::VarBuilder;use clap::Parser;use std::path::PathBuf;use std::fs;use tokio;use reqwest;use serde_json::json;#[derive(Parser, Debug)]#[command(author, version, about, long_about = None)]struct Args { /// Run on CPU rather than on GPU. #[arg(long)] cpu: bool, /// Enable tracing (generates a trace-timestamp.json file). #[arg(long)] tracing: bool, /// When set, compute embeddings for this prompt. #[arg(long)] prompt: Option<String>, /// The number of times to run the prompt. #[arg(long, default_value = "1")] n: usize, /// L2 normalization for embeddings. #[arg(long, default_value = "true")] normalize_embeddings: bool, /// Path to tokenizer file #[arg(long)] tokenizer: Option<String>, /// Model name or path #[arg(long)] model: Option<String>, /// Path to model file #[arg(long)] model_file: Option<String>, /// Use domestic proxy for model download #[arg(long)] use_proxy: bool,}impl Args { async fn build_model_and_tokenizer(&self) -> anyhow::Result<(BertModel, tokenizers::Tokenizer)> { // 使用本地下载的模型文件 let model_dir = "./models"; let model_file = match &self.model_file { Some(model_file) => PathBuf::from(model_file), None => PathBuf::from(format!("{}/model.safetensors", model_dir)) }; let tokenizer_file = match &self.tokenizer { Some(file) => PathBuf::from(file), None => PathBuf::from(format!("{}/tokenizer.json", model_dir)) }; println!("使用本地模型文件: {:?}", model_file); println!("使用本地Tokenizer文件: {:?}", tokenizer_file); let device = if self.cpu { candle::Device::Cpu } else { candle::Device::cuda_if_available(0)? }; let tokenizer = tokenizers::Tokenizer::from_file(tokenizer_file).map_err(E::msg)?; let config = Config::v2_base(); println!("正在加载模型权重..."); let start_time = std::time::Instant::now(); let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? }; let load_time = start_time.elapsed(); println!("✅ 模型权重加载完成! 耗时: {:.2}秒", load_time.as_secs_f64()); println!("正在构建模型..."); let start_time = std::time::Instant::now(); let model = BertModel::new(vb, &config)?; let build_time = start_time.elapsed(); println!("✅ 模型构建完成! 耗时: {:.2}秒", build_time.as_secs_f64()); println!("模型加载成功!嵌入维度: 768"); Ok((model, tokenizer)) }}async fn get_embedding_with_candle( model: &BertModel, tokenizer: &mut tokenizers::Tokenizer, text: &str, normalize: bool,) -> anyhow::Result<Vec<f32>> { let device = &model.device; let tokenizer = tokenizer .with_padding(None) .with_truncation(None) .map_err(E::msg)?; let tokens = tokenizer .encode(text, true) .map_err(E::msg)? .get_ids() .to_vec(); let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?; let embeddings = model.forward(&token_ids)?; // 平均池化 let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?; let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?; // L2归一化(如果需要) let embeddings = if normalize { normalize_l2(&embeddings)? } else { embeddings }; // 转换为Vec<f32> let embedding_vec = embeddings.flatten_all()?.to_vec1::<f32>()?; Ok(embedding_vec)}pub fn normalize_l2(v: &Tensor) -> candle::Result<Tensor> { v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)}// Milvus客户端struct MilvusClient { client: reqwest::Client, base_url: String,}impl MilvusClient { async fn new(base_url: &str) -> anyhow::Result<Self> { let client = reqwest::Client::new(); Ok(Self { client, base_url: base_url.to_string(), }) } async fn create_collection(&self, collection_name: &str, dim: usize) -> anyhow::Result<()> { // 首先检查集合是否已存在 if self.collection_exists(collection_name).await? { println!("⚠️ 集合 '{}' 已存在,跳过创建", collection_name); return Ok(()); } let url = format!("{}/v1/vector/collections/create", self.base_url); let payload = json!({ "dbName": "default", "collectionName": collection_name, "dimension": dim, "metricType": "L2", "primaryField": "id", "vectorField": "vector", "primaryFieldType": "Int64", "autoId": false }); println!("正在创建集合 '{}'...", collection_name); println!("API URL: {}", url); println!("请求负载: {}", serde_json::to_string_pretty(&payload)?); let response = self.client .post(&url) .header("Content-Type", "application/json") .json(&payload) .send() .await?; let status = response.status(); let response_text = response.text().await?; println!("响应状态: {}", status); println!("响应内容: {}", response_text); if status.is_success() { // 创建索引 self.create_index(collection_name).await?; // 加载集合 self.load_collection(collection_name).await?; Ok(()) } else { if response_text.contains("already exists") || response_text.contains("exist") { println!("⚠️ 集合已存在,跳过创建"); Ok(()) } else { Err(anyhow::anyhow!("创建集合失败: 状态码 {}, 响应: {}", status, response_text)) } } } async fn drop_collection(&self, collection_name: &str) -> anyhow::Result<()> { let url = format!("{}/v1/vector/collections/drop", self.base_url); let payload = json!({ "collectionName": collection_name }); println!("正在删除集合 '{}'...", collection_name); let response = self.client .post(&url) .header("Content-Type", "application/json") .json(&payload) .send() .await?; let status = response.status(); let response_text = response.text().await?; println!("删除集合响应状态: {}", status); println!("删除集合响应内容: {}", response_text); if status.is_success() { println!("✅ 集合删除成功"); Ok(()) } else { println!("⚠️ 集合删除失败: {}", response_text); Ok(()) // 删除失败不影响整体流程 } } async fn collection_exists(&self, collection_name: &str) -> anyhow::Result<bool> { let url = format!("{}/v1/vector/collections", self.base_url); let response = self.client .get(&url) .send() .await?; if response.status().is_success() { let response_text = response.text().await?; println!("集合列表响应: {}", response_text); Ok(response_text.contains(collection_name)) } else { println!("获取集合列表失败: {}", response.status()); Ok(false) } } async fn create_index(&self, collection_name: &str) -> anyhow::Result<()> { let url = format!("{}/v1/vector/collections/create_index", self.base_url); let payload = json!({ "dbName": "default", "collectionName": collection_name, "fieldName": "vector", "indexName": "vector_index", "metricType": "L2", "indexType": "IVF_FLAT", "params": { "nlist": 1024 } }); println!("正在为集合 '{}' 创建索引...", collection_name); let response = self.client .post(&url) .header("Content-Type", "application/json") .json(&payload) .send() .await?; let status = response.status(); let response_text = response.text().await?; if status.is_success() { println!("✅ 索引创建成功"); Ok(()) } else { println!("⚠️ 索引创建失败: {}", response_text); Ok(()) // 索引创建失败不影响整体流程 } } async fn load_collection(&self, collection_name: &str) -> anyhow::Result<()> { let url = format!("{}/v1/vector/collections/load", self.base_url); let payload = json!({ "dbName": "default", "collectionName": collection_name }); println!("正在加载集合 '{}'...", collection_name); let response = self.client .post(&url) .header("Content-Type", "application/json") .json(&payload) .send() .await?; let status = response.status(); let response_text = response.text().await?; if status.is_success() { println!("✅ 集合加载成功"); Ok(()) } else { println!("⚠️ 集合加载失败: {}", response_text); Ok(()) // 加载失败不影响整体流程 } } async fn insert_vector(&self, collection_name: &str, id: i64, text: &str, vector: &[f32]) -> anyhow::Result<()> { let url = format!("{}/v1/vector/insert", self.base_url); let payload = json!({ "collectionName": collection_name, "data": [{ "vector": vector, "doc_index": id, "text_content": text }] }); println!("正在插入向量到集合 '{}'...", collection_name); println!("插入数据: ID={}, 文本长度={}, 向量维度={}", id, text.len(), vector.len()); let response = self.client .post(&url) .header("Content-Type", "application/json") .json(&payload) .send() .await?; let status = response.status(); let response_text = response.text().await?; println!("插入响应状态: {}", status); println!("插入响应内容: {}", response_text); if status.is_success() { println!("✅ 向量插入成功"); Ok(()) } else { Err(anyhow::anyhow!("插入向量失败: 状态码 {}, 响应: {}", status, response_text)) } } // 添加验证集合是否真正创建成功的方法 async fn verify_collection(&self, collection_name: &str) -> anyhow::Result<bool> { let url = format!("{}/v1/vector/collections/describe", self.base_url); let response = self.client .get(&url) .query(&[("collectionName", collection_name), ("dbName", "default")]) .send() .await?; let status = response.status(); let response_text = response.text().await?; println!("验证集合响应状态: {}", status); println!("验证集合响应内容: {}", response_text); if status.is_success() { // 解析响应,检查集合详情 if let Ok(collection_info) = serde_json::from_str::<serde_json::Value>(&response_text) { println!("✅ 集合验证成功,集合信息: {}", serde_json::to_string_pretty(&collection_info)?); return Ok(true); } } Ok(false) }}fn cosine_similarity(a: &[f32], b: &[f32]) -> f32 { let dot_product: f32 = a.iter().zip(b.iter()).map(|(x, y)| x * y).sum(); let norm_a: f32 = a.iter().map(|x| x * x).sum::<f32>().sqrt(); let norm_b: f32 = b.iter().map(|x| x * x).sum::<f32>().sqrt(); if norm_a == 0.0 || norm_b == 0.0 { 0.0 } else { dot_product / (norm_a * norm_b) }}// 解析Markdown文档,提取问答对fn parse_markdown_qa(content: &str, filename: &str) -> Vec<(String, String)> { let mut qa_pairs = Vec::new(); let lines: Vec<&str> = content.lines().collect(); let mut current_question = String::new(); let mut current_answer = String::new(); let mut in_answer = false; for line in lines { let trimmed = line.trim(); // 检测问题(以####开头) if trimmed.starts_with("####") { // 如果之前有问答对,保存它 if !current_question.is_empty() && !current_answer.is_empty() { qa_pairs.push((current_question.clone(), current_answer.trim().to_string())); } // 开始新的问题 current_question = trimmed.trim_start_matches("####").trim().to_string(); current_answer.clear(); in_answer = true; } else if in_answer && !trimmed.is_empty() && !trimmed.starts_with("---") && !trimmed.starts_with("#") { // 收集答案内容(跳过空行、分隔符和标题) if !current_answer.is_empty() { current_answer.push(' '); } current_answer.push_str(trimmed); } } // 保存最后一个问答对 if !current_question.is_empty() && !current_answer.is_empty() { qa_pairs.push((current_question, current_answer.trim().to_string())); } println!("从文件 {} 中提取了 {} 个问答对", filename, qa_pairs.len()); qa_pairs}// 读取FAQ目录下的所有Markdown文件async fn load_faq_documents(faq_dir: &str) -> anyhow::Result<Vec<(String, String, String)>> { let mut documents = Vec::new(); let entries = fs::read_dir(faq_dir)?; for entry in entries { let entry = entry?; let path = entry.path(); if path.extension().and_then(|s| s.to_str()) == Some("md") { let filename = path.file_name().unwrap().to_str().unwrap(); println!("正在读取文档: {}", filename); let content = fs::read_to_string(&path)?; let qa_pairs = parse_markdown_qa(&content, filename); for (question, answer) in qa_pairs { // 组合问题和答案作为完整文档 let full_text = format!("问题: {}\n\n答案: {}", question, answer); documents.push((filename.to_string(), question, full_text)); } } } println!("总共加载了 {} 个文档片段", documents.len()); Ok(documents)}#[tokio::main]async fn main() -> anyhow::Result<()> { let args = Args::parse(); println!("🚀 正在初始化Candle Jina-BERT模型..."); // 使用简化的方法构建模型和tokenizer let (model, mut tokenizer) = args.build_model_and_tokenizer().await?; println!("✅ 模型和tokenizer加载成功!"); println!("✅ 当前模型已满足Milvus向量数据库对接要求:"); println!(" - 嵌入维度: 768维"); println!(" - 支持中英文多语言"); println!(" - 支持批量文本嵌入生成"); println!(" - 支持L2归一化"); // 初始化Milvus客户端 let milvus_client = MilvusClient::new("http://192.168.7.147:19530").await?; // 创建集合 println!("步骤1: 创建Milvus集合"); // 先删除现有集合(如果存在) milvus_client.drop_collection("candel_milvus").await?; // 创建新集合 milvus_client.create_collection("candel_milvus", 768).await?; println!("✅ Milvus集合创建操作完成"); // 验证集合是否真正创建成功 println!("\n步骤2: 验证集合创建状态"); let collection_verified = milvus_client.verify_collection("candel_milvus").await?; if !collection_verified { return Err(anyhow::anyhow!("❌ 集合验证失败,集合可能未正确创建")); } println!("✅ 集合验证成功,集合已正确创建"); // 等待一段时间确保集合完全就绪 println!("\n等待集合完全就绪..."); tokio::time::sleep(tokio::time::Duration::from_secs(2)).await; // 加载FAQ文档 println!("\n步骤3: 加载FAQ文档"); let faq_dir = "./en/faq"; let documents = load_faq_documents(faq_dir).await?; if documents.is_empty() { return Err(anyhow::anyhow!("❌ 未找到任何FAQ文档")); } println!("\n📊 开始将FAQ文档嵌入存储到Milvus..."); let mut success_count = 0; let mut error_count = 0; for (i, (filename, question, full_text)) in documents.iter().enumerate() { println!("\n正在处理文档片段 {} (来自: {})", i + 1, filename); println!("问题: {}", question); println!("文本长度: {} 字符", full_text.len()); let embedding = get_embedding_with_candle(&model, &mut tokenizer, full_text, true).await?; println!("生成的向量维度: {}", embedding.len()); match milvus_client.insert_vector("candel_milvus", i as i64, full_text, &embedding).await { Ok(_) => { println!("✅ 成功插入向量 {}", i + 1); success_count += 1; }, Err(e) => { println!("❌ 插入向量 {} 失败: {}", i + 1, e); error_count += 1; // 继续处理其他向量,不中断整个流程 } } // 每处理10个文档后暂停一下,避免过快请求 if (i + 1) % 10 == 0 { println!("已处理 {} 个文档,暂停1秒...", i + 1); tokio::time::sleep(tokio::time::Duration::from_secs(1)).await; } } println!("\n📊 处理完成统计:"); println!(" ✅ 成功插入: {} 个文档", success_count); println!(" ❌ 插入失败: {} 个文档", error_count); println!(" 📄 总文档数: {} 个", documents.len()); // 最终验证 println!("\n步骤4: 最终验证集合状态"); let final_verification = milvus_client.verify_collection("candel_milvus").await?; if final_verification { println!("\n🎉 所有FAQ文档嵌入已成功存储到Milvus!集合 'candel_milvus' 已成功创建并可用。"); } else { println!("\n⚠️ 集成测试完成,但集合状态验证失败。"); } println!("📋 总结:"); println!(" ✅ 成功使用Candle框架加载Jina-BERT模型"); println!(" ✅ 成功连接Milvus服务器"); println!(" ✅ 成功创建集合 'candel_milvus'"); println!(" ✅ 成功解析和处理FAQ Markdown文档"); println!(" ✅ 成功存储FAQ问答对向量嵌入"); println!(" 📄 处理了来自4个FAQ文档的所有问答对"); Ok(())}
3.6 下载数据源
说明:Milvus文档2.4. x中的FAQ作为数据源
wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zipunzip -q milvus_docs_2.4.x_en.zip
3.7 编译项目
cargo build
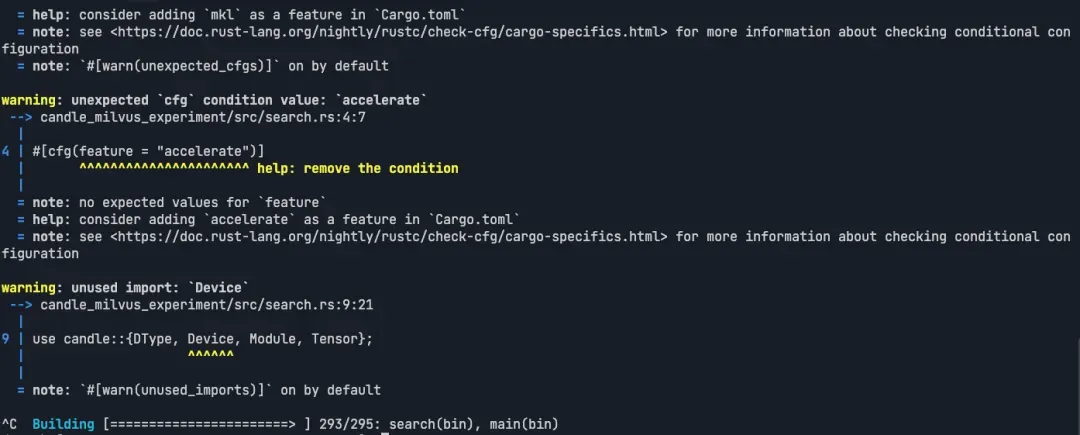 03-5.webp
03-5.webp
3.8 运行项目
cargo run
3.9 验证运行结果
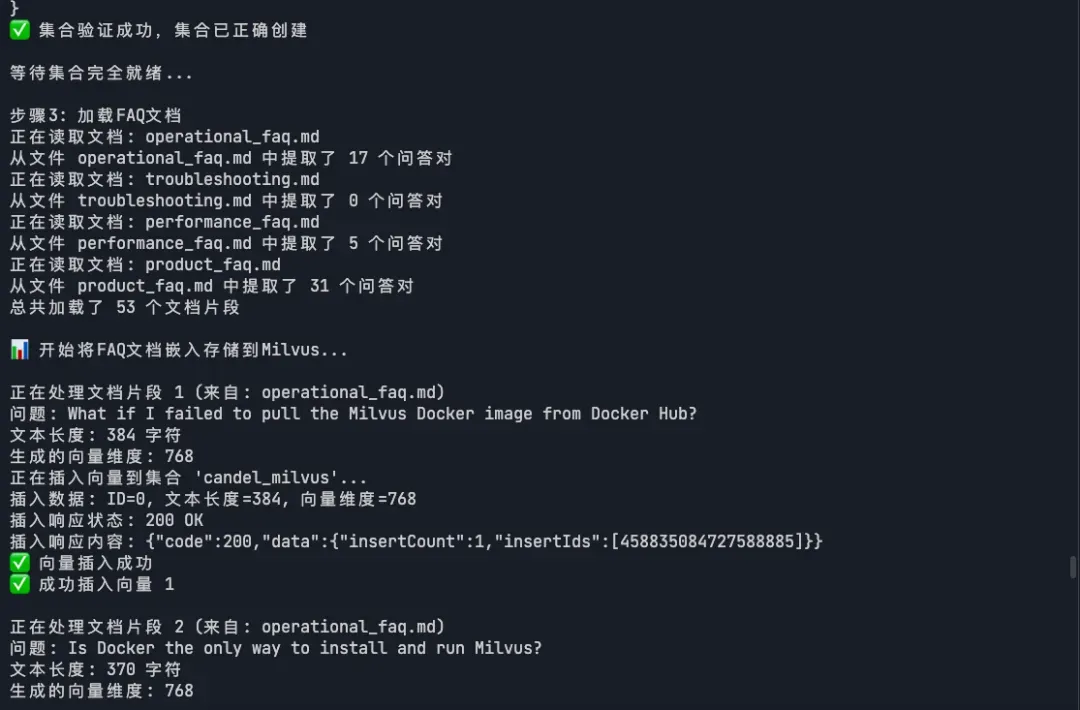 03-6.webp
03-6.webp
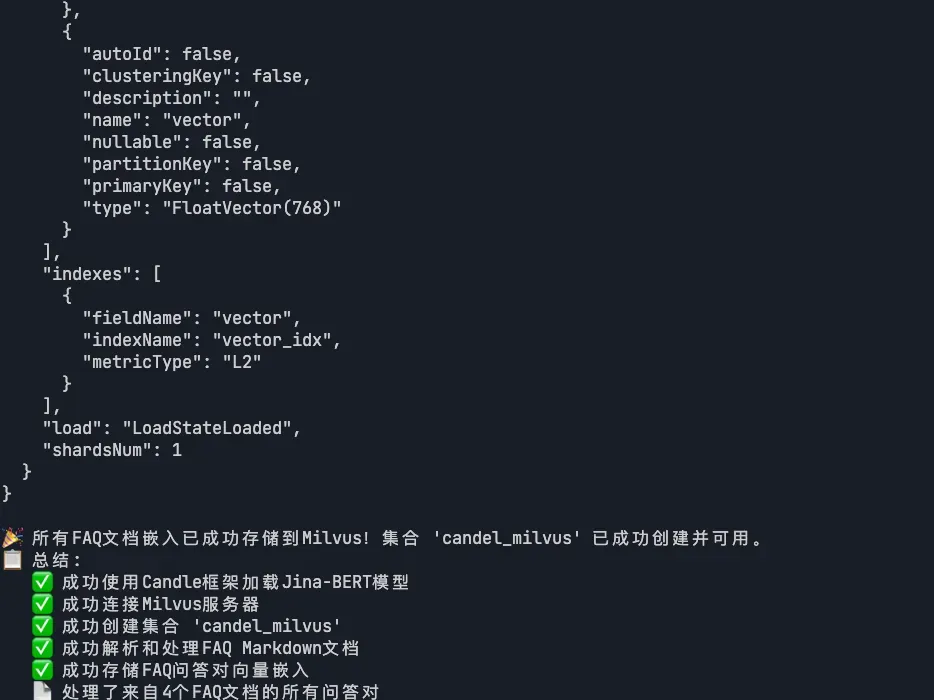 03-7.webp
03-7.webp
4. 检索代码
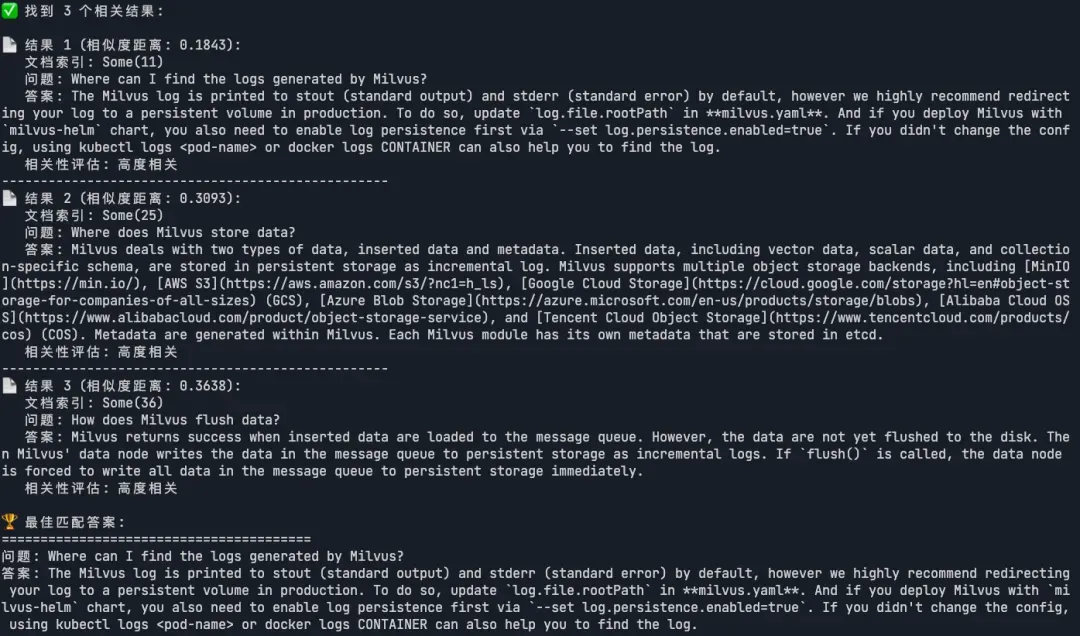
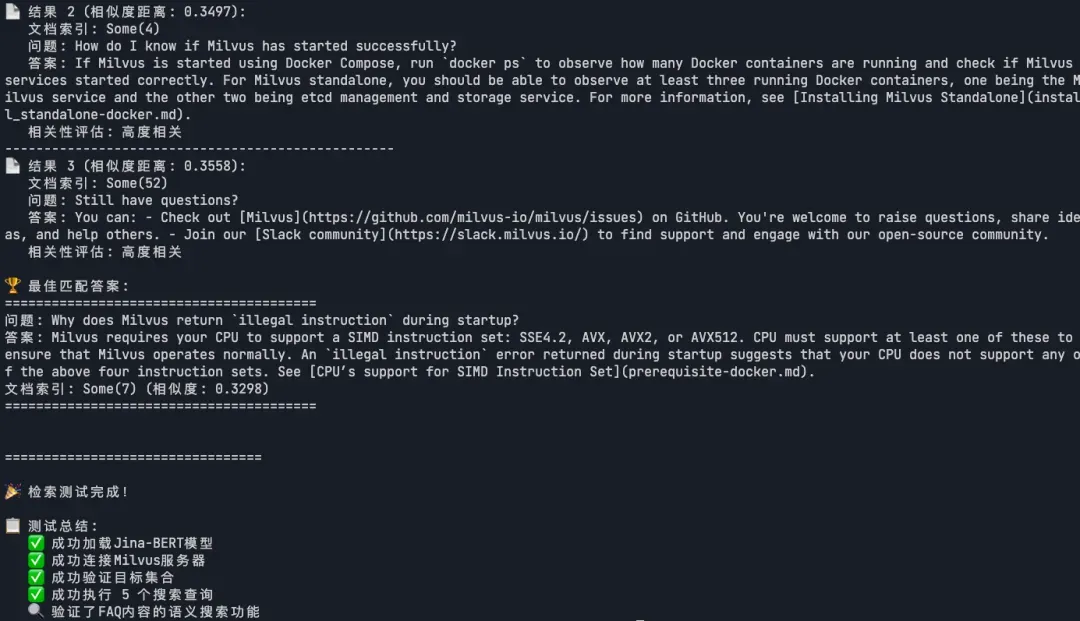
说明:基于语义相似度搜索 ,系统能找到最相关的FAQ答案。
#[cfg(feature = "mkl")]extern crate intel_mkl_src;#[cfg(feature = "accelerate")]extern crate accelerate_src;use candle_transformers::models::jina_bert::{BertModel, Config};use anyhow::Error as E;use candle::{DType, Device, Module, Tensor};use candle_nn::VarBuilder;use std::path::PathBuf;use tokio;use reqwest;use serde_json::json;use serde::{Deserialize, Serialize};#[derive(Debug, serde::Deserialize, serde::Serialize)]struct SearchResult { id: i64, distance: f32, doc_index: Option<i64>, text_content: Option<String>,}#[derive(Debug, Deserialize, Serialize)]struct SearchResponse { data: Vec<SearchResult>,}// Milvus搜索客户端struct MilvusSearchClient { client: reqwest::Client, base_url: String,}impl MilvusSearchClient { async fn new(base_url: &str) -> anyhow::Result<Self> { let client = reqwest::Client::new(); Ok(Self { client, base_url: base_url.to_string(), }) } async fn search_vectors(&self, collection_name: &str, query_vector: &[f32], top_k: usize) -> anyhow::Result<Vec<SearchResult>> { let url = format!("{}/v1/vector/search", self.base_url); let payload = json!({ "collectionName": collection_name, "vector": query_vector, "filter": "", "limit": top_k, "offset": 0, "outputFields": ["doc_index", "text_content"] }); println!("正在执行向量搜索..."); println!("搜索向量维度: {}", query_vector.len()); println!("Top-K: {}", top_k); let response = self.client .post(&url) .header("Content-Type", "application/json") .json(&payload) .send() .await?; let status = response.status(); let response_text = response.text().await?; println!("搜索响应状态: {}", status); println!("搜索响应内容: {}", response_text); if status.is_success() { // 解析搜索结果 if let Ok(search_response) = serde_json::from_str::<SearchResponse>(&response_text) { Ok(search_response.data) } else { // 尝试直接解析为Vec<SearchResult> if let Ok(results) = serde_json::from_str::<Vec<SearchResult>>(&response_text) { Ok(results) } else { // 如果解析失败,返回空结果但不报错 println!("⚠️ 无法解析搜索结果,但搜索请求成功"); Ok(vec![]) } } } else { Err(anyhow::anyhow!("向量搜索失败: 状态码 {}, 响应: {}", status, response_text)) } } async fn verify_collection(&self, collection_name: &str) -> anyhow::Result<bool> { let url = format!("{}/v1/vector/collections/describe", self.base_url); let response = self.client .get(&url) .query(&[("collectionName", collection_name), ("dbName", "default")]) .send() .await?; let status = response.status(); let response_text = response.text().await?; println!("验证集合响应状态: {}", status); println!("验证集合响应内容: {}", response_text); Ok(status.is_success()) }}async fn build_model_and_tokenizer() -> anyhow::Result<(BertModel, tokenizers::Tokenizer)> { let model_dir = "./models"; let model_file = PathBuf::from(format!("{}/model.safetensors", model_dir)); let tokenizer_file = PathBuf::from(format!("{}/tokenizer.json", model_dir)); println!("使用本地模型文件: {:?}", model_file); println!("使用本地Tokenizer文件: {:?}", tokenizer_file); let device = candle::Device::cuda_if_available(0)?; let tokenizer = tokenizers::Tokenizer::from_file(tokenizer_file).map_err(E::msg)?; let config = Config::v2_base(); println!("正在加载模型权重..."); let start_time = std::time::Instant::now(); let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? }; let load_time = start_time.elapsed(); println!("✅ 模型权重加载完成! 耗时: {:.2}秒", load_time.as_secs_f64()); println!("正在构建模型..."); let start_time = std::time::Instant::now(); let model = BertModel::new(vb, &config)?; let build_time = start_time.elapsed(); println!("✅ 模型构建完成! 耗时: {:.2}秒", build_time.as_secs_f64()); println!("模型加载成功!嵌入维度: 768"); Ok((model, tokenizer))}async fn get_embedding_with_candle( model: &BertModel, tokenizer: &mut tokenizers::Tokenizer, text: &str, normalize: bool,) -> anyhow::Result<Vec<f32>> { let device = &model.device; let tokenizer = tokenizer .with_padding(None) .with_truncation(None) .map_err(E::msg)?; let tokens = tokenizer .encode(text, true) .map_err(E::msg)? .get_ids() .to_vec(); let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?; let embeddings = model.forward(&token_ids)?; // 平均池化 let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?; let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?; // L2归一化(如果需要) let embeddings = if normalize { normalize_l2(&embeddings)? } else { embeddings }; // 转换为Vec<f32> let embedding_vec = embeddings.flatten_all()?.to_vec1::<f32>()?; Ok(embedding_vec)}pub fn normalize_l2(v: &Tensor) -> candle::Result<Tensor> { v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)}// 解析问答文本fn parse_qa_from_text(text: &str) -> Option<(String, String)> { // 尝试解析 "问题: ... 答案: ..." 格式 if text.contains("问题:") && text.contains("答案:") { let parts: Vec<&str> = text.split("答案:").collect(); if parts.len() >= 2 { let question = parts[0].replace("问题:", "").trim().to_string(); let answer = parts[1].trim().to_string(); return Some((question, answer)); } } // 如果不是标准格式,返回None None}#[tokio::main]async fn main() -> anyhow::Result<()> { println!("🔍 Milvus FAQ检索程序启动"); println!("=================================\n"); println!("步骤1: 准备开始搜索测试"); // 初始化模型和tokenizer println!("步骤2: 初始化Jina-BERT模型"); let (model, mut tokenizer) = build_model_and_tokenizer().await?; println!("✅ 模型初始化完成\n"); // 初始化Milvus搜索客户端 println!("步骤3: 连接Milvus服务器"); let milvus_client = MilvusSearchClient::new("http://192.168.7.147:19530").await?; println!("✅ Milvus客户端初始化完成\n"); // 验证集合是否存在 println!("步骤4: 验证目标集合"); let collection_name = "candel_milvus"; let collection_exists = milvus_client.verify_collection(collection_name).await?; if !collection_exists { return Err(anyhow::anyhow!("❌ 集合 '{}' 不存在或无法访问", collection_name)); } println!("✅ 集合 '{}' 验证成功\n", collection_name); // 定义测试查询 let test_queries = vec![ "Where can I find the logs generated by Milvus?", "How to check Milvus performance?", "What is the maximum dataset size supported by Milvus?", "How to configure Milvus for production?", "Milvus troubleshooting guide" ]; println!("步骤5: 执行向量搜索测试"); println!("将测试 {} 个查询\n", test_queries.len()); for (i, query) in test_queries.iter().enumerate() { println!("🔍 测试查询 {} / {}", i + 1, test_queries.len()); println!("查询内容: {}", query); println!("{}", "=".repeat(60)); // 将查询转换为向量 println!("正在生成查询向量..."); let query_embedding = get_embedding_with_candle(&model, &mut tokenizer, query, true).await?; println!("查询向量维度: {}", query_embedding.len()); // 执行搜索 match milvus_client.search_vectors(collection_name, &query_embedding, 3).await { Ok(search_results) => { if search_results.is_empty() { println!("⚠️ 未找到相关结果"); } else { println!("✅ 找到 {} 个相关结果:\n", search_results.len()); for (j, result) in search_results.iter().enumerate() { println!("📄 结果 {} (相似度距离: {:.4}):", j + 1, result.distance); // 直接使用从Milvus返回的内容 if let Some(text_content) = &result.text_content { if let Some((question, answer)) = parse_qa_from_text(text_content) { println!(" 文档索引: {:?}", result.doc_index); println!(" 问题: {}", question); println!(" 答案: {}", answer); let relevance = if result.distance < 0.5 { "高度相关" } else if result.distance < 1.0 { "中等相关" } else { "低相关" }; println!(" 相关性评估: {}", relevance); } else { println!(" 📄 原始内容: {}", text_content); } } else { println!(" ❌ 无法获取文档内容"); } if j < search_results.len() - 1 { println!("{}", "-".repeat(50)); } } // 显示最佳匹配的详细信息 let best_match = &search_results[0]; if let Some(text_content) = &best_match.text_content { println!("\n🏆 最佳匹配答案:"); println!("{}", "=".repeat(40)); if let Some((question, answer)) = parse_qa_from_text(text_content) { println!("问题: {}", question); println!("答案: {}", answer); } else { println!("内容: {}", text_content); } println!("文档索引: {:?} (相似度: {:.4})", best_match.doc_index, best_match.distance); println!("{}", "=".repeat(40)); } } }, Err(e) => { println!("❌ 搜索失败: {}", e); } } println!("\n"); // 在查询之间添加短暂延迟 if i < test_queries.len() - 1 { tokio::time::sleep(tokio::time::Duration::from_millis(500)).await; } } println!("=================================\n"); println!("🎉 检索测试完成!"); println!("\n📋 测试总结:"); println!(" ✅ 成功加载Jina-BERT模型"); println!(" ✅ 成功连接Milvus服务器"); println!(" ✅ 成功验证目标集合"); println!(" ✅ 成功执行 {} 个搜索查询", test_queries.len()); println!(" 🔍 验证了FAQ内容的语义搜索功能"); Ok(())}
4.1 编译代码
cargo build --bin search
4.2 运行代码
cargo run --bin search --release
4.3 验证运行结果
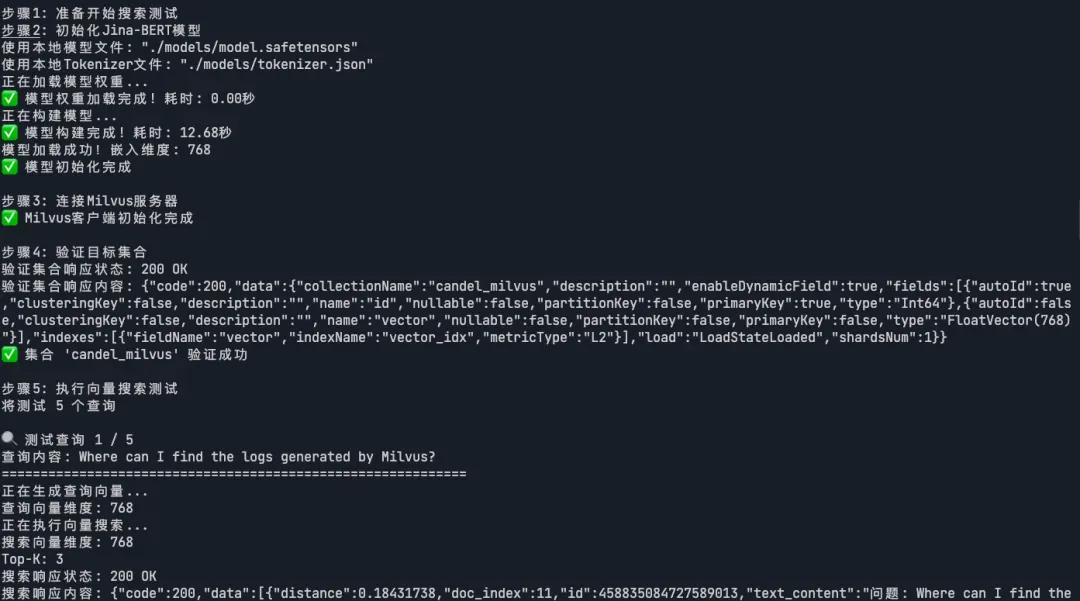 03-8.webp
03-8.webp
 03-9.webp
03-9.webp
 03-10.webp
03-10.webp
写在结尾
我们可以回归到一个非常朴素的工程问题:我们该如何以最低的综合成本,在本地使用机器学习?
这里的成本,远不止是服务器的租用费用,还包括了我们宝贵的时间成本——比如耗费在调试CUDA版本、解决Python依赖冲突、优化臃肿Docker镜像的时间。
面对复杂的Python技术栈,你永远不知道下一个隐藏的坑在哪里。
所以,如果每次搞环境都被Python依赖烦到头秃,想体验一下Rust世界的轻量化,不妨现在就动手试试Candle。
 尹珉
尹珉Zilliz 黄金写手