



Milvus Week | 脱离生产环境的Benchmark ,谁信谁就输了

前言
POC是行业照妖镜,能让所有毫无意义的刷榜原形毕露。
但一个诡异的现象是:人人厌恶刷榜,但人人参与刷榜。
所以,先说一句不中听的话:大部分Benchmark对生产毫无助力,但是在帮助混子掩人耳目上大放异彩。
这一点,在向量数据库Benchmark上尤是如此。自2023年向量数据库赛道爆火,一夜之前,各种自研向量数据库刷榜各种Benchmark,结果一刷就爆、一用就废,甚至耽误项目进度,一度差点毁了整个行业的口碑。
比如,传统Benchmark中会通常假设:数据已经全部导入,索引已经完全建立。但在真实生产中,数据是持续流入的,系统不可能为了一次索引重建就停机几个小时。
再比如,Elasticsearch 对外宣传是毫秒级查询速度,但实际上,光是优化索引的过程就需要 20 多小时。但现实中,不可能有人在做AI应用的时候,能忍受这么久的停摆,不仅如此,还需要坐待实时响应不断动态更新。
当然,刷榜没错,错的是多数Benchmark指标太悬浮,与生产脱节。这就给了很多混子产品浑水摸鱼的机会,也逼着很多想要正经做研发、解决客户问题的企业,被迫参与恶性内卷,浪费时间精力。
也是因此,基于多年一线实战经验,我们推出了 VDBBench——完全开源的向量数据库Benchmark,专为“模拟真实生产环境”而生:重点考量持续写入、动态过滤、实时索引等实用性能指标 。
01
为什么传统Benchmark无法用于生产
传统向量数据库Benchmark与生产有多脱节,案例不胜枚举,影响最大的主要集中在三处:
1、数据集维度过时
很多基准测试还在用 SIFT 或 GloVe,但是SIFT 只有 128 维,而 OpenAI、Cohere 的主流模型的embedding模型维度是 768~3072 维,这些数据集的维度远低于当前大模型生成的embedding维度。
2、测试方法存在瑕疵
尤其是在并发测试吞吐量时,设定的并发数量和并发机制不能测试出database最佳性能。
3、测试用例过于简单
现实中,用户查询往往是这样的:一边是数据持续写入,一边是需要复杂的元数据过滤。但市面上的Benchmark基本没有考虑到这一点,大多只跑最基础的查询前先写完数据、建完索引之类 Hello World 级别的测试。
02
VDBBench 如何还原真实生产场景?
基于以上问题,VDBBench 彻底放弃对已有Benchmark做简单迭代,选择直接从零构建,过程中唯一的指导原则就是:真实、真实、还是真实。
围绕向量数据库的使用场景,我们将真实可以分为三个维度:
真实的数据、真实的工作负载、真实的性能测试方式。
(1)真实的数据
我们对用于向量数据库Benchmark的数据集进行了全面升级。用最新的embedding模型生成的向量数据,彻底取代 SIFT 和 GloVe 这类古董数据集。
为了确保数据在RAG之类的场景中真实可用,我们精心挑选了覆盖真实企业和垂直行业场景的文本语料。这些数据包括从通用知识库到生物医学问答、大规模网页搜索等多种类型,全面覆盖当代 AI 应用的主流需求。
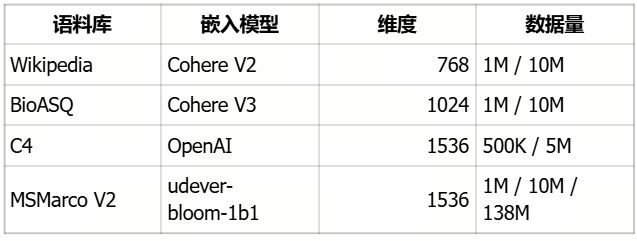
Datasets used in VDBBench
此外,VDBBench 还支持自定义数据集。你可以使用自己通过embedding模型生成的数据,针对特定工作负载进行测试。这使得Benchmark的测试结果能够直接反映真实生产环境。
说白了,外面再吹得天花乱坠的数据,都没有企业自己的真实数据能说明问题。
(2)真实的工作负载
在全新的 VDBBench 中,我们将性能评估的重点聚焦于真正影响生产环境中用户体验的指标设计,比如:
- 使用 P95/P99 延迟衡量真实用户体验
平均延迟或中位数延迟并不总能反映真实体验。对用户来说,更重要的是尾部延迟——也就是 P95(95 分位)或 P99(99 分位)延迟。在 VDBBench 中,我们专门测量这两个指标,从而揭示在真实场景中,95% 或 99% 的查询实际能达到的性能表现。
- 报告系统可持续承载的 QPS,而非短暂峰值
VDBBench 不重点关注昙花一现的性能峰值,因为这个指标注水空间太大,因此我们通过逐步增加并发负载,找出系统在稳定运行条件下可长期维持的最大查询吞吐量(max_qps)。这才是衡量数据库真实处理能力的关键指标。
- 公开 Recall,将性能指标锚定于准确性
在向量搜索中,速度很重要,但不是唯一的重点,如果没有准确率(recall)的配合,这种性能数据本身毫无意义。
VDBBench 在每一项测试中都附带对应的 Recall 值,让用户能够准确了解当前性能下的查询准确度。这样,才能实现系统间真正公平、具备生产参考价值的横向对比。
(3)真实的性能测试方式
VDBBench 的设计核心在于还原真实使用场景,而非理想化的实验室条件。其中一个关键思路是将串行测试与并发测试分开进行,以更全面地捕捉系统在不同负载下的表现。例如,对于延迟指标,我们会分别记录:
serial_latency_p99:衡量系统在极低负载下(即一次只处理一个请求)时的性能,代表理想延迟的最佳情况。
conc_latency_p99:衡量系统在高并发条件下(即同时接收多个请求)时的响应能力,更贴近真实生产环境中的用户体验。
我们将基准测试划分为两个主要阶段:
串行测试(Serial Test)
该阶段为单进程运行,共执行 1,000 次查询,用于建立理想情况下的性能和准确率基线,包括 serial_latency_p99 和 recall。
并发测试(Concurrency Test)
该阶段模拟生产环境中的实际负载压力,具体设计如下:
真实的客户端模拟:每个测试进程独立运行,拥有自己的连接和查询集合,避免测试进程间互相通信干扰结果。
同步启动:所有测试进程同时开始,确保测得的 QPS 真正反映设定并发下的系统吞吐能力。
通过这些严谨设计,VDBBench 提供的 max_qps和 conc_latency_p99 指标具备高度可信度,可直接用于用户的生产能力规划与系统评估。
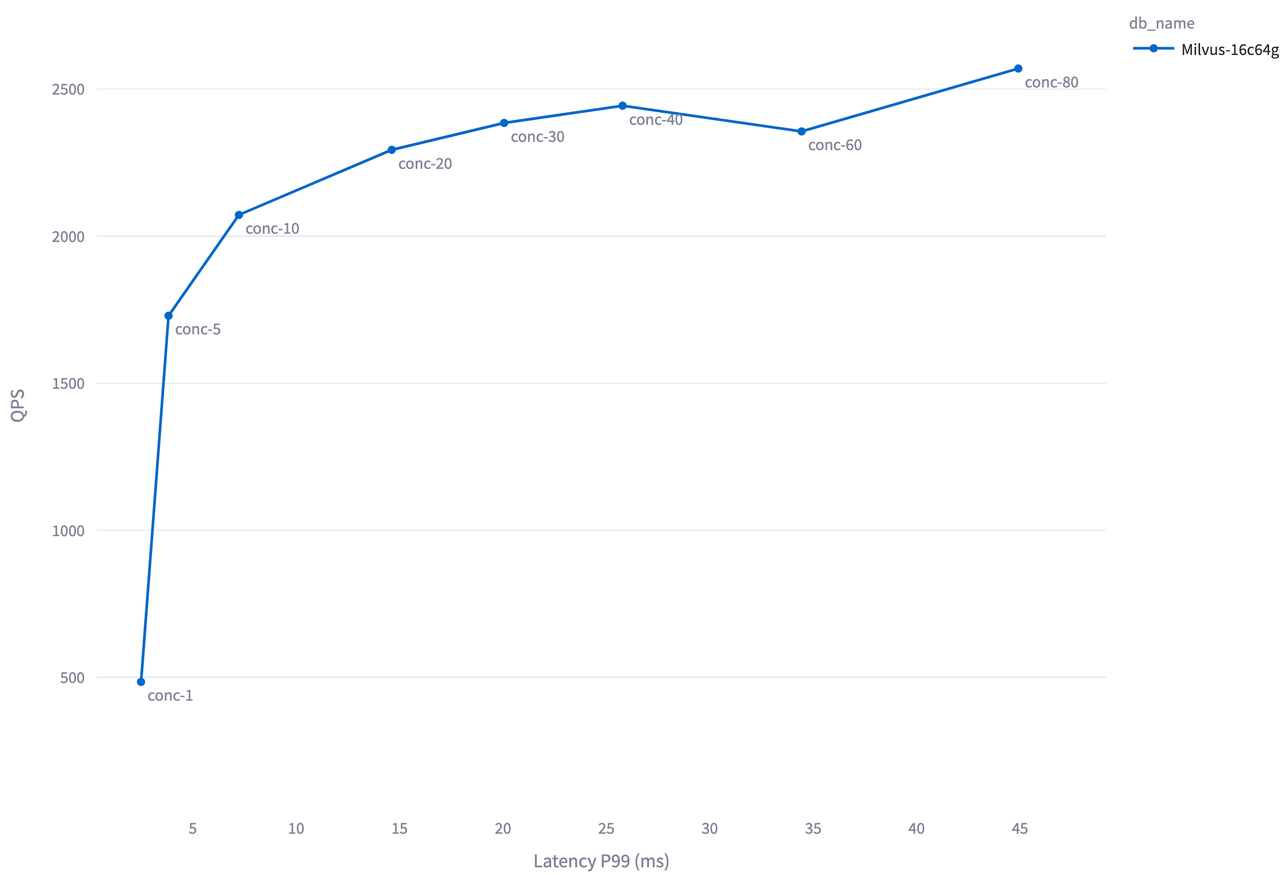
Milvus-16c64g-standalone 在 Cohere 1M 测试下不同并发等级的 QPS 和延迟表现如下:
在这个例子中,并发数低于 20 时,Milvus 处于负载不足的状态,增加并发有助于更好地利用系统资源,因此 QPS 提高。 但当并发超过 20 后,Milvus 达到饱和负载,继续增加并发不会带来更多 QPS,反而因为排队时间变长,延迟上升。
03
不止静态数据搜索:更贴近真实生产场景
VDBBench 是目前唯一覆盖完整生产关键场景的向量数据库Benchmark工具,不止涵盖静态数据集,也对过滤查询以及流式数据等多种真实场景中的常见情况做了考量。
(1)静态数据集(Static Collection)
市面上多数Benchmark会直接进行查询测试,但VDBBench 会首先确保每个数据库都完成了索引优化,从而提供全链路视角:
数据写入时间(ingestion time)
索引优化时间(optimizing time):即优化索引至最优状态所花费的时间,这会直接影响后续查询性能
在索引完全优化后的搜索性能表现(同时测试串行和并发两种条件下)
(2)元数据过滤(Filtering)
在实际生产环境中,向量搜索通常需要结合元数据过滤,比如“找出价格低于 $100、长得像这张图的鞋子”。这种带过滤条件的搜索会增加整体系统复杂度,主要体现在两方面:
过滤复杂度(Filter Complexity):涉及的标量字段越多、逻辑条件越复杂,可能导致召回不足、图索引变成孤岛等等情况。
过滤选择性(Filter Selectiveness):这是我们在真实生产中反复验证的“隐藏性能杀手”。过滤条件变“挑剔”之后,可能导致recall的波动,QPS 甚至会波动几个数量级。
VDBBench可以 针对不同的过滤量(从 50% 到 99.9%)进行系统测试,全面评估数据库在这一关键生产场景下的处理能力,提供更具现实意义的性能画像。
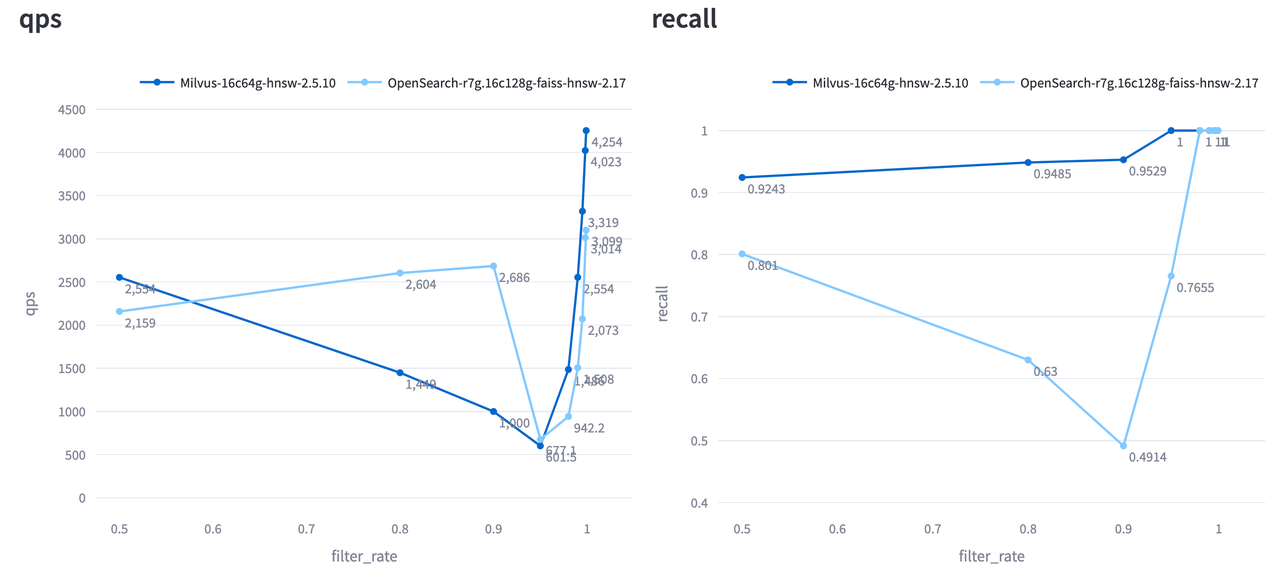
Milvus 和 OpenSearch 在 Cohere 1M 测试中,不同过滤选择性条件下的 QPS 和召回率表现如下。X 轴表示通过过滤的样本占比(Filtered Percentage)。
可以看到,Milvus 在不同过滤条件下始终保持了极高的召回率,而 OpenSearch 的表现则不稳定,看似QPS表现较好,但是recall < 0.8在生产中常常是不可接受的。
(3)流式场景(Streaming)
生产环境中的数据很少是静态的,我们通常在新数据持续写入的同时还要执行搜索。这也是许多在静态Benchmark中数据刷爆的数据库“翻车”的根本原因。
VDBBench 独特的流式测试用例专注于 “边写入边搜索” 的性能,重点考察两个方面:
其一,数据量增长的影响:随着数据规模扩大,搜索性能是否稳定、如何变化。
其二,写入负载的影响:并发写入是否拖慢了搜索性能,因为写入也会消耗系统的 CPU 和内存资源。
流式场景是一种更全面的压力测试。而设计这样的Benchmark本身也很有挑战,因为目标不是简单地描述某个数据库的表现,而是要提供一个公平、可比较的评估模型,让你能够放心地对不同数据库的表现进行横向比较。
我们在支持用户使用多种向量数据库进行 POC(概念验证)时积累了丰富经验,并据此构建了结构化的测试方法:VDBBench 允许你预先设定写入速率(以目标负载为依据),确保每个数据库承受的是完全一致的压力,从而使搜索性能具有可比性。
例如,在 Cohere 10M 数据集和设定 500 行/秒写入速率的测试中:
VDBBench 启动 5 个数据写入进程,每个进程以 100 行/秒的速度写入。
每写入完 10% 的数据,就进行一次搜索测试(包含串行与并发模式),并记录相关指标,包括延迟、QPS 和召回率。
这种可控的测试方法,清晰揭示了数据库在真实生产负载下性能的演变轨迹,帮助你判断系统在持续写入压力下是否可靠。
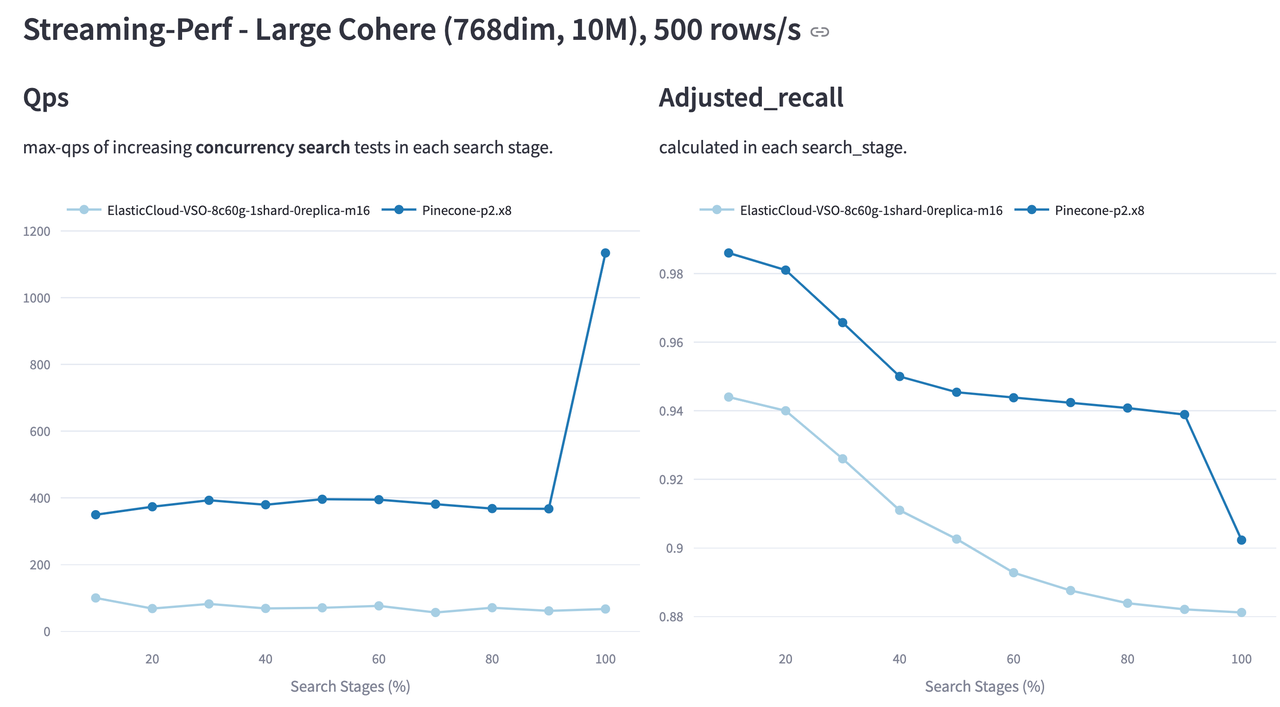
在 Cohere 10M 流式测试(500 行/秒写入速率)中,Pinecone 与 ElasticSearch 的 QPS 和召回率表现如下:
Pinecone 在整个测试过程中维持了更高的 QPS 和召回率,尤其在数据插入完成(达到 100%)后,QPS 表现出显著提升。
但不止如此,VDBBench 更进一步,还支持可选的索引优化步骤,让用户可以对比索引优化前后的搜索性能差异。
同时,VDBBench 还会记录并报告每个阶段的实际耗时,为用户提供更深入的洞察,帮助理解系统在接近真实生产环境下的效率与行为模式。
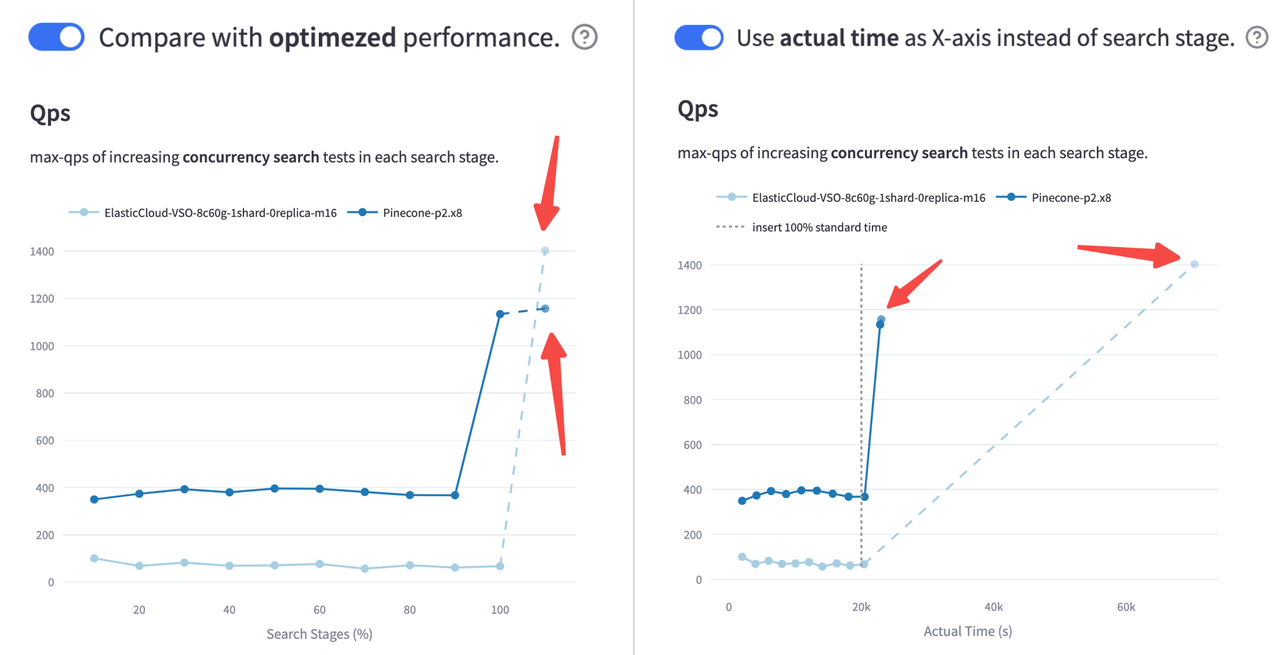
ElasticSearch 优化后性能反超?(左图)
将 X 轴改为实际耗时后再看——索引优化太久了!(右图)
总结
别再被“假数字”骗了
前面说了那么多,其实总结起来就是一句话,别迷信数据,更别迷信对生产效益不大的数据。
相比传统Benchmark,VDBBench 通过覆盖持续数据写入、元数据过滤和流式负载等关键场景,能够更贴近实际生产环境。
尝鲜链接: https://github.com/zilliztech/VectorDBBench
(全面的过滤case和streaming case将随vdbbench 1.0发布,目前可在vdbbench 1.0分支中进行preview)
但是,不要迷信任何纸面数据,再细致的Benchmark设计,也永远无法覆盖所有真实场景中千变万化的客户需求。
 田敏
田敏


