



开源向量数据库性能对比: Milvus, Chroma, Qdrant
一、前言
为应对公司在大规模文本、图像等非结构化数据处理上的业务增长需求,笔者着手调研当前流行的开源向量数据库。主要针对查询速度、并发度和召回率这几大核心维度进行深入分析,以确保选定的数据库方案能够在实际业务场景中高效应对大规模数据检索和高并发需求。通过全面对比不同数据库的表现,得出可靠的调研结论。
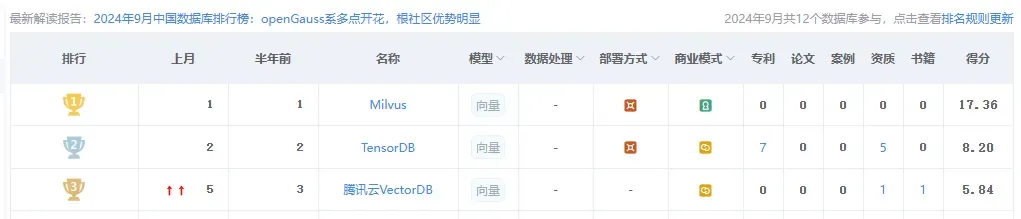
笔者首先在墨天轮排行榜中查看了国产向量数据库的排行情况。前三名分别是 Milvus、TensorDB、腾讯云VectorDB。Milvus 是一个非常受欢迎的开源向量数据库,目前在GitHub上已经有30K的star,足以说明它的关注度非常的高。TensorDB 是爱可生的闭源向量数据库,想使用只能走商业途径。腾讯云VectorDB 从名字上就能看出来是腾讯的向量数据库,它也是闭源的,但是可以在腾讯云上申请试用。试用的配置只有1核,1G内存,20G磁盘空间,不满足笔者的测试需求。
 1.webp
1.webp
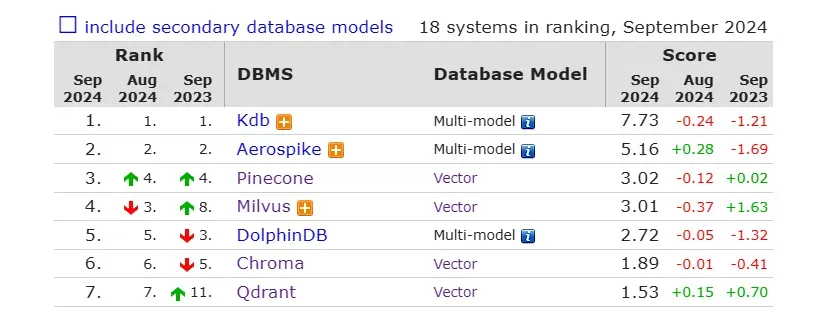
目前看来,只有 Milvus 能满足开源的测试条件。看来笔者不能局限在国产数据库了,于是在 DB-Engines 排行榜,笔者找到了前几名的纯向量数据库 Pinecone、Milvus、Chroma、Qdrant。其中只有 Pinecone 是闭源的,只能通过云来访问使用。所以接下来笔者会对 Milvus、Chroma、Qdrant 三个数据库做一次性能测试。
 2.webp
2.webp
PS:想了解向量数据库能力相关的比对(包括数据库架构、支持的索引类型、不同的特性等等),可以移步到 zilliz 官网中查看详细信息:Vector Database Comparison (zilliz.com)
二、性能测试工具的选择
现在已经找到了需要测试的开源向量数据库,下一步当然是挑选测试的工具啦。在评估向量数据库的过程中,ANN Benchmark 和 VectorDBBench 是两个常用的性能测试工具。他们也有各自的优缺点:
ANN Benchmark 是一种外部性能测试工具,专门用于评估不同的向量索引算法在真实数据集上的性能。向量索引是向量数据库中资源消耗大的组件,其性能直接影响整个数据库的表现。ANN Benchmark 在评估向量索引算法方面表现出色,有助于选择和比较不同的向量搜索库。然而,它并不适用于评估复杂且成熟的向量数据库系统,也未能涵盖如“向量搜索+条件过滤”这样的情形。
VectorDBBench 是一个为开源向量数据库(如 Milvus 和 Weaviate)以及全托管向量数据库服务(如 Zilliz Cloud 和 Pinecone)设计的开源性能测试工具。它支持查看向量数据库的 QPS 和召回率。VectorDBBench 专为向量数据库全面评估而设计。它关注资源消耗、数据加载能力和系统稳定性等因素。VectorDBBench 能够进行的测试更接近真实世界的生产环境。
为了更全面且真实的测试,笔者最后选择了 VectorDBBench 测试工具。
PS:VectorDBBench 已经做过一些基准测试,并且把结果公布在官网中了,可以到这里查看:VectorDBBench —— 向量数据库性能测试工具 (zilliz.com.cn)
三、向量数据库的本地部署
本次测试,三个数据库都会用docker的方式部署在一台 12c64g 的CentOS7的机器上,每次测试只启动其中一个数据库的 docker 实例来保证测试数据的正确性。
1、Qdrant 部署
最新的版本是 1.11.5,本次部署为此版本。
# 从 Dockerhub 下载最新的 Qdrant 镜像
docker pull qdrant/qdrant
#运行服务
docker run -d -p 6333:6333 -p 6334:6334 \
-v /home/caiyfc/Qdrant/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
Qdrant 现在可以访问:
REST API:http://localhost:6333/
Web 用户界面:http://localhost:6333/dashboard
GRPC API:http://localhost:6334/
2、Chroma 部署
本次使用的版本是 v0.5.8.dev16
推荐使用 pip install chromadb 部署。但是为了方便测试,所以这里使用docker部署。
# 从 Dockerhub 下载最新的 chroma 镜像
docker pull chromadb/chroma:0.5.8.dev16
#运行服务,由于 VectorDBBench 连接 Chroma,必须输入密码,所以这里需要先创建一个密码
docker run -d -p 6335:8000 -e CHROMADB_DB_PASSWORD='admin123' chromadb/chroma:0.5.8.dev16
注意:笔者在后续的测试过程中发现,chroma 选择了不同向量维度的测试用例时,会出现一种向量维度的测试用例能正常测试,而另一种必然会失败。在排查之后发现,chroma 的docker 实例中,是有报错的:
 3.webp
3.webp
这是说明当前的配置不允许执行 "重置" 操作,所以在一种向量维度的测试用例完成后,VectorDBBench 在 drop old collection 时,会失败,导致无法切换到另一个向量维度。所以在部署的时候要加上环境变量ALLOW_RESET=TRUE,命令是:
docker run -d -p 6335:8000 -e CHROMADB_DB_PASSWORD='admin123' -e ALLOW_RESET=TRUE chromadb/chroma:0.5.8.dev16
3、Milvus 部署
本次使用的版本是 v2.4.5
# Download the installation script
$ curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# Start the Docker container
$ bash standalone_embed.sh start
# 集群管理
# Stop Milvus
$ bash standalone_embed.sh stop
# Delete Milvus data
$ bash standalone_embed.sh delete
 4.webp
4.webp
至此,三个数据库已经全部部署成功。接下来就要开始部署 VectorDBBench 了。
四、VectorDBBench 本地部署及使用
本次是在 win11 操作系统上直接部署的,机器的cpu是i5-8600K,内存16G。
# 先决条件 python >= 3.11
pip install vectordb-bench
# 安装执行客户端
pip install vectordb-bench[qdrant]
pip install vectordb-bench[chromadb]
#启动
init_bench
启动之后,会自动打开浏览器,并进入VectorDBBench 的主页,其中显示了 VectorDBBench 提供的标准基准测试结果,此外,用户自己执行的所有测试的结果也将在此处显示。
 5.webp
5.webp
笔者需要自己来进行测试,所以直接选择了“Run Your Test”的功能。
 6.webp
6.webp
点击“Run Your Test”按钮之后,需要选择待测试的向量数据库。如果内置的没有想要测试的数据库,那可以根据GitHub的例子手动增加:zilliztech/VectorDBBench: A Benchmark Tool for VectorDB (github.com)
 7.webp
7.webp
选择好了待测试数据库,需要填写上对应数据库的连接信息:
PS:为了避免干扰,本次测试每次只选择一个数据库进行测试,并关闭其他两个数据库的 Docker 实例。虽然可以同时选择并填写多个数据库,VectorDBBench 也会进行串行测试,但为了更好地记录数据库使用系统资源的情况,分开测试能够减少干扰,记录更准确的结果。
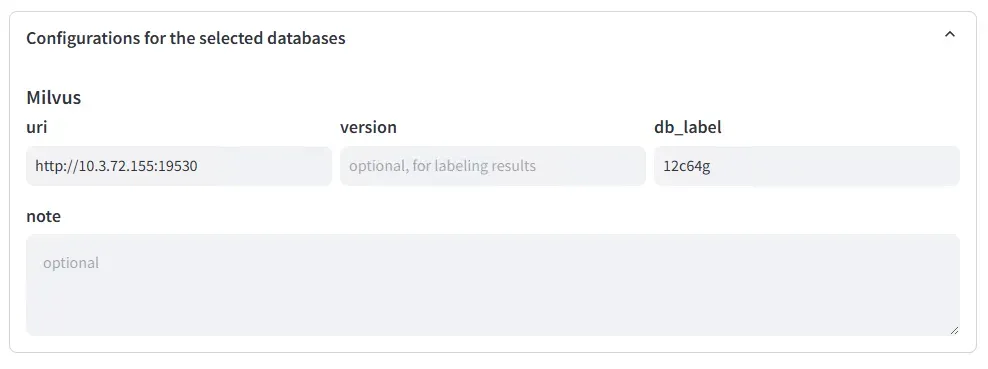 8.webp
8.webp
由于资源不够,测试用例统一选择如下,在不同的数据量及不同的向量维度下来进行测试,其他设置保持默认。
 9.webp
9.webp
 10.webp
10.webp
 11.webp
11.webp
 12.webp
12.webp
 13.webp
13.webp
 14.webp
14.webp
然后点击 “Run Your Test” 就可以开始测试。
 15.webp
15.webp
在测试过程中,如果发现测试结果有失败的情况,可以查看 VectorDBBench 的输出,里面会有详细的报错情况。笔者就遇到了一次报错:
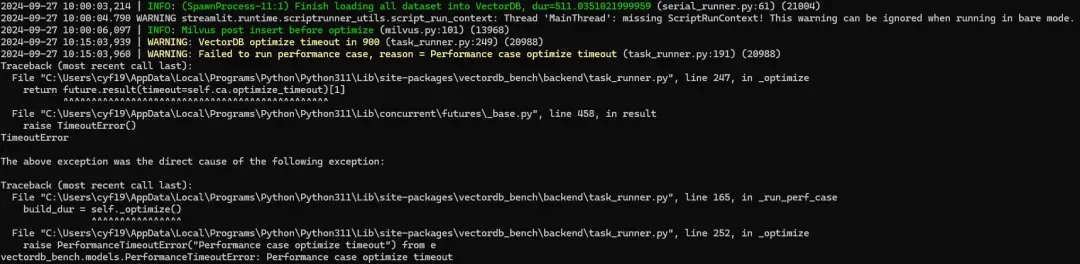 16.webp
16.webp
这里提示了:
vectordb_bench.models.PerformanceTimeoutError: Performance case optimize timeout
说明这是超时导致的报错。需要修改参数,由于笔者在win11中部署的 VectorDBBench ,所以配置文件在:
C:\Users\xxxx\AppData\Local\Programs\Python\Python311\Lib\site-packages\vectordb_bench\__init__.py
修改如下参数,并重启 VectorDBBench 即可:
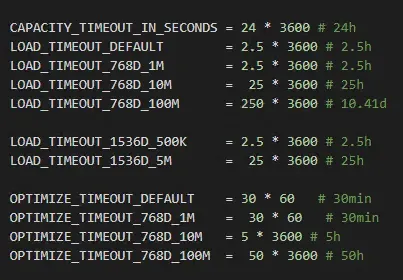 17.webp
17.webp
五、测试结果
1、资源消耗情况
资源消耗需要观察CPU使用率、内存消耗、磁盘IO及网络情况,所以笔者在另外一台虚拟机中搭建了 prometheus + grafana 的监控体系。并且在向量数据库的机器上安装了 node_exporter,给 prometheus 提供实时的监控数据。
Qdrant:
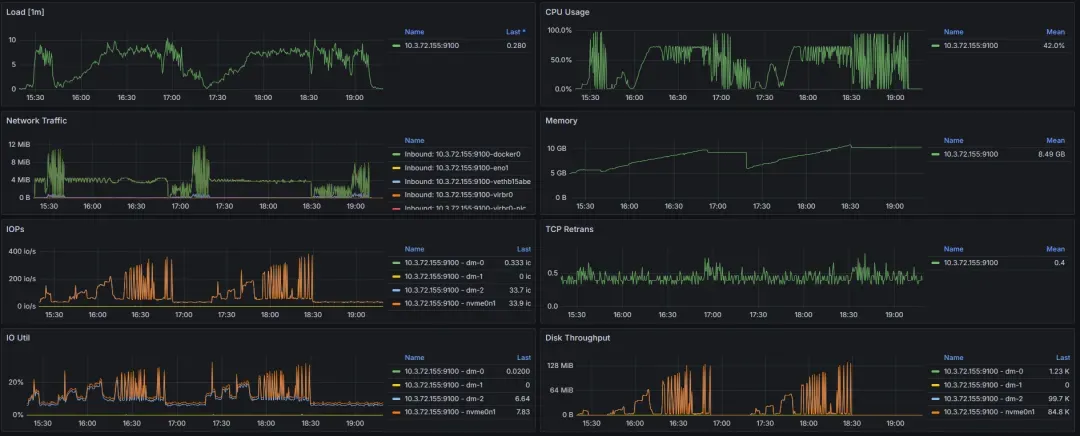 18.webp
18.webp
Chroma:
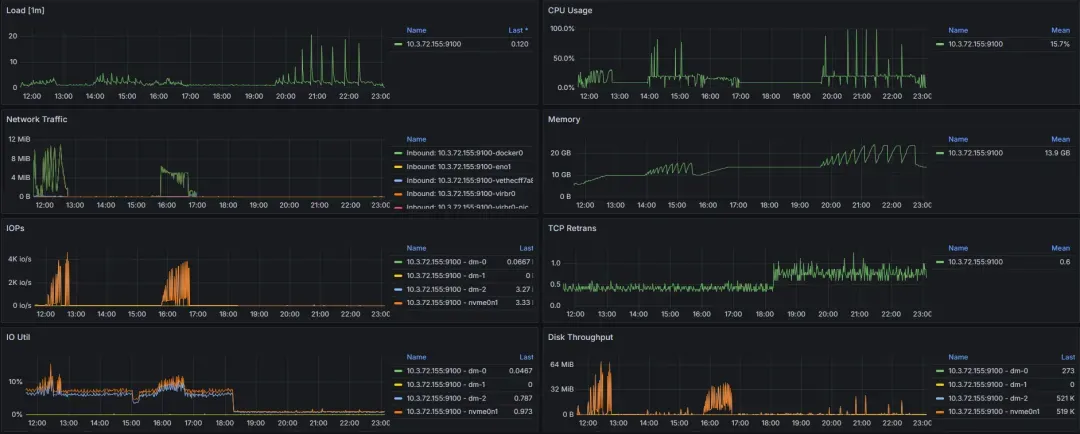 19.webp
19.webp
Milvus:
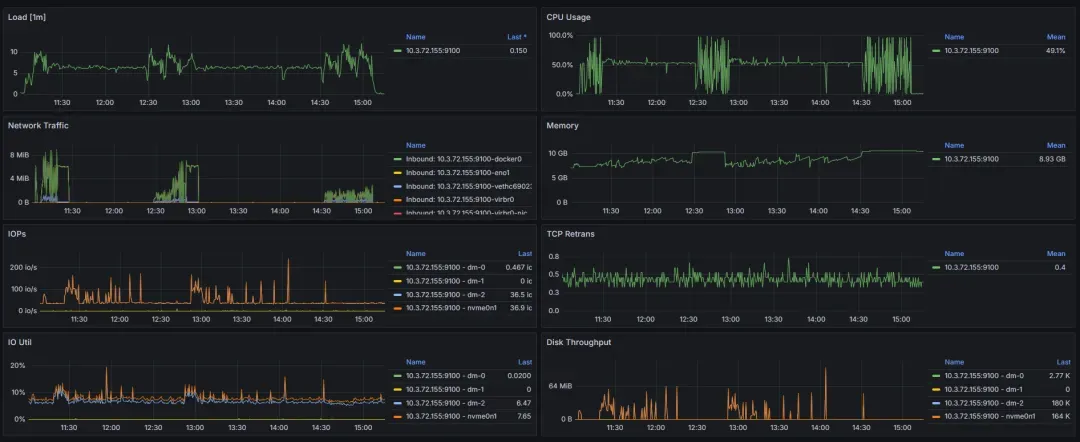 20.webp
20.webp
2、性能指标情况
性能指标主要从以下四个方面来体现:
QPS (Queries Per Second):
每秒处理的查询数量。QPS 是衡量系统查询处理能力的指标,越高的 QPS 表示系统能够在单位时间内处理更多的查询。
Recall:
是检索系统的准确率指标,用来衡量查询结果中返回的相关项与实际相关项的比例。Recall 越高,表示返回的查询结果中包含更多正确的匹配项。用来评估系统在近似查询时的效果。
Load Duration:
数据加载时间,表示将数据加载到数据库中所花费的总时间。这个指标衡量数据库的加载效率,通常数据量越大,加载时间越长。
Serial Latency P99:
这是 99% 的查询处理时间的上限,表示系统处理 99% 的查询所需的最长时间(99th percentile latency)。这个指标是用来衡量系统响应时间的一致性,值越低,系统的响应越稳定。P99 延迟越高意味着系统偶尔会有慢查询。
性能测试的结果如下如图:
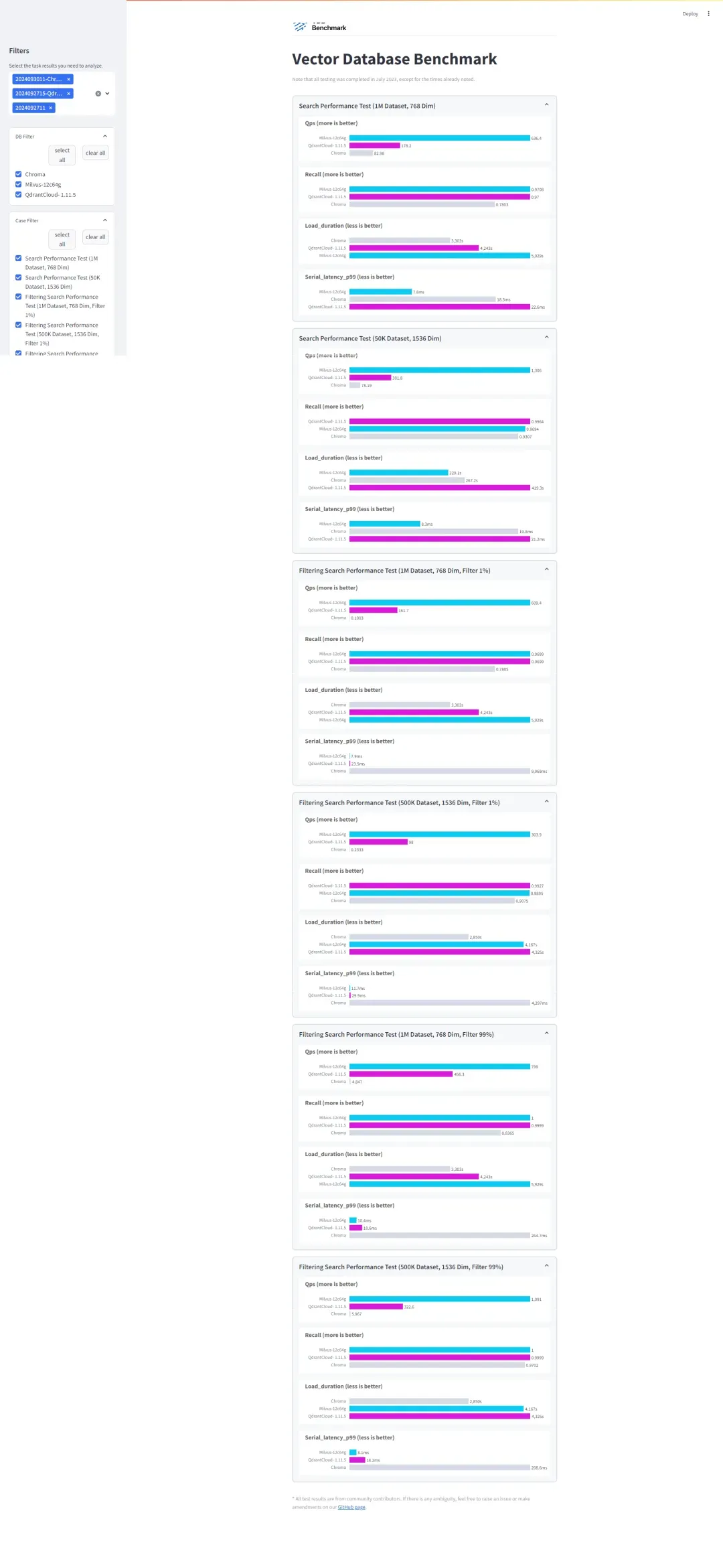 21.webp
21.webp
3、测试总结
Qdrant:
优点:中规中矩,Qps 相对较高、延迟相对较低。在CPU和磁盘IO方面的利用率较高,能够在处理高负载时提供较好的性能。
缺点:在大数据集的加载时间和总体检索精度上略逊于 Milvus,适合对过滤查询有需求但不追求极端性能的场景。对CPU和内存的需求较大,尤其在高并发和复杂查询时可能会出现较高的资源消耗,导致系统负载上升。
Chroma:
优点:对于较小的数据集,Chroma 更容易上手和集成。对CPU的依赖较低,更多依赖内存来处理大规模数据。
缺点:性能在 Qps、Recall、加载时间和延迟方面都不如 Milvus 和 Qdrant,尤其是在大规模和高并发场景下表现较差。并且内存消耗较大,在长时间运行时对系统的内存要求较高,可能会影响其他应用程序的运行。
Milvus:
优点:整体性能最强,尤其是在 Qps、Recall、加载时间和延迟方面都表现优异,适合大规模、高并发的向量查询场景。且CPU与内存使用率的控制较为出色。
缺点:大数据集的加载时间还有提升的空间,整体上仍然表现出色。
根据测试结果来看,Milvus 是当前最优的选择,适合处理大规模数据集和对性能要求较高的应用。Qdrant 则中规中矩,有着较低的延迟,适合规模不大且对延迟有高要求的应用,而 Chroma 更适合小规模、低负载的应用。
参考文献
[1] 向量数据库性能测试技巧
 蔡一凡
蔡一凡Zilliz 黄金写手


