先分块再向量化已经过时!先embedding再chunking才是王道
在RAG应用开发中,第一步就是对文档进行chunking,chunk的质量将直接决定整个RAG检索的效果。
过去,行业通常采用先chunking再embedding的做法,这种思路中,chunking环节无论是固定长度分块,还是递归分块,其实都解决不了精度和上下文平衡的问题。
在此背景下,先embedding再chunking的思路逐渐被更多人接受。
典型代表是Jina AI提出的Late Chunking策略,以及Max–Min semantic chunking。Late Chunking详见Late Chunking×Milvus:如何提高RAG准确率。
本文将对Max–Min semantic chunking进行重点解读。
01 常见chunk思路解读
一个典型的RAG流程如下:
第一步:数据清洗与处理
去除无关内容(如页眉页脚、乱码),统一格式,并将长文本分割成短片段(如500字/段),避免在向量表示时丢失细节。第二步:向量生成与存储
使用embedding模型(如OpenAI的text-embedding-3-small、LangChain的BAAI embedding)将每个文本片段转换成向量(Embedding),并将其存储到向量数据库(如Milvus、Zilliz Cloud)。数据库通过不同索引方式优化语义检索效率。第三步:查询
将用户的自然语言查询(如“RAG如何解决大模型幻觉问题”)通过相同的embedding模型转换成向量后,向量数据库根据查询向量,快速找到语义最相似的Top-K个文本片段。第四步:生成回答
将检索到的Top-K文本片段作为上下文,与用户的原始查询一起拼接成提示词(Prompt),传给大模型,大模型据此生成回答。
在这个过程中,高效的文档分块是整个流程中的第一步。它将文档拆成小块(一个段落、一节或一组句子),有效提高后续召回内容的准确性和细节丰富度。
然而,做好高质量的chunking并不容易。
目前行业有两种常见的分块方法:
固定大小分块:
简单粗暴,按固定的字符数或token数来切分。优点是效率高,但没有语法和语义意识,随便切割,容易让句子甚至单词断裂,直接导致不连贯。递归字符分块:
这个方法比固定大小聪明些,按优先级(如段落、换行符、句子等)逐步切分。优点是简单且有语义感,能保证块内的一定连贯性,但可能仍然存在断层。并且,部分文档可能缺乏清晰结构,或章节、段落长度差异过大,这会影响检索算法向LLM提供最优相关文本的能力;此外,该方法还可能生成超出LLM上下文窗口的分块。
在这两种方式下分块时,我们经常要考虑两个问题:精度和上下文的平衡。
越小的块,精度越高,但上下文可能不全;越大的块,语境更完整,但可能包含太多无关信息。
2025年,Bhat等人的研究发现,分块大小这个问题没有标准答案,但整体上,事实类问题适合小块(64-128 token),而叙事类问题则适合大块(512-1024 token)。
那么,有没有更聪明一点的办法,不完全依赖于长度限制的分块思路?
答案是有的——Max–Min semantic chunking。
02 Max–Min semantic chunking 解读
Max–Min semantic chunking的核心是通过动态语义评估来实现分块优化。
相比传统的RAG流程(先chunking再embedding),Max–Min semantic chunking会先对所有句子进行embedding,然后在此基础上进行分块。
Max–Min semantic chunking将分块任务视为动态/时序聚类问题:基于句向量的相似度,将不同句子组合成新的分块。
与传统聚类方法不同,该方法需尊重文档中句子的时序性——即同一聚类内的句子必须连续。算法会按顺序逐句处理文档,决定每个句子是加入当前分块,还是开启新分块。
具体步骤如下:
生成embedding并初步聚类:
首先使用文本嵌入模型,将所有句子映射到高维空间。设文档包含n个句子,通过计算,已将前n-k个句子归入当前分块C。此时需决策:n-k+1个句子,是加入分块C,还是创建新分块。计算分块内最小相似度:
计算当前分块C内所有句子向量间的最小pairwise余弦相似度,识别分块内语义最不相似的句子对,衡量分块内句子的关联紧密程度,进而判断新句子是否与分块内句子足够相似。计算新句子与分块的最大相似度:
计算当前分块C内所有句子的最大余弦相似度,对比新句子与现有分块的最高语义相似度。分块决策依据:
核心决策逻辑为:若分块C内的最小相似度小于新句子与分块C的最大相似度,则新句子加入分块C,否则开启新分块。阈值调整(分块大小优化):
可以动态调整分块大小、相似度阈值等参数来优化块内语义相关度。初始化处理(分块中仅有单个句子时):
当当前分块仅包含1个句子时,需特殊处理初始化问题,直接对比第一句与第二句相似度与我们设置的阈值常数,高于常数就算入同一个分块,低于常数就开启新的分块。
03 Max–Min semantic chunking的优劣势
Max–Min semantic chunking的创新点有三:
动态分块逻辑:
摒弃固定尺寸或结构依赖的静态规则,以“句子语义相似度”为核心决策依据。具体流程为:先计算当前分块内句子的最小语义相似度,再计算新句子与当前分块的最大语义相似度;若最大相似度高于最小相似度,则将新句子纳入当前分块,否则启动新分块。轻量化参数设计:
仅需调整3个核心超参数(最大分块大小、一二句之间的最低语义相似度需求、新句子与块内句子最大相似度的最低门槛),且超参数逻辑与分块大小自适应 —— 分块规模越大,新句子纳入的阈值越高。计算资源复用:
复用RAG系统原生所需的“句子嵌入向量”(无需额外计算嵌入),仅在分块阶段增加轻量化的余弦相似度计算,整体计算开销低于传统语义分块方法。
Max–Min semantic chunking的不足:
由于依据时序聚类,处理长文档时可能会丢失文档中长距离的上下文依赖关系。如果关键信息散落在多个文本块中,脱离上下文的文本分块片段可能失去原有意义,导致召回效果差。
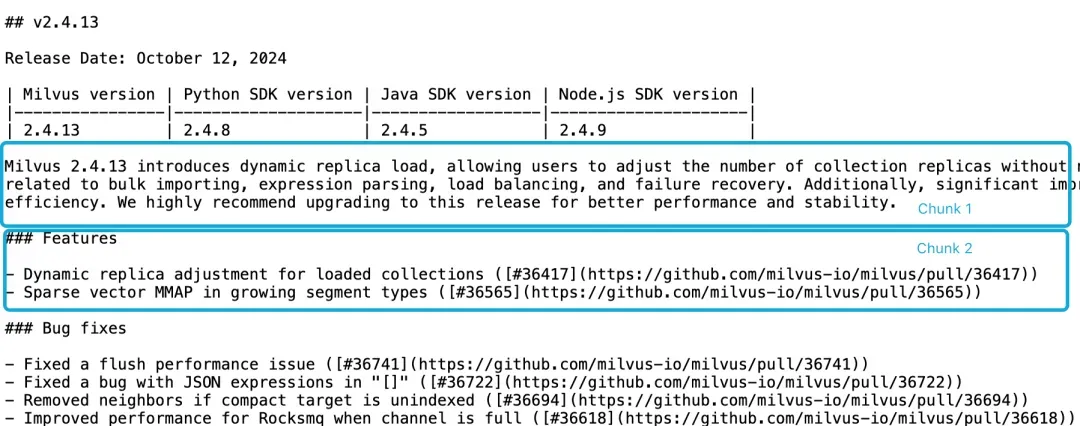
例如,如果我们查询Milvus 2.4.13有哪些新功能?,直接相关内容在分块2里,而Milvus版本信息在分块1里,Embedding模型很难正确链接这些内容,产生不高质量的Embedding。
 05-04-1.webp
05-04-1.webp
如果功能描述与版本信息不在同一个分块里,且缺乏更大的上下文文档,LLM难以解决关联问题。
为了解决这一问题,我们可以采用滑动窗口重新采样、重叠的上下文窗口长度以及多次文档扫描等方式。
 Zilliz
Zilliz