开源!DeepSeek+DeepSearcher+硅基流动,打造私有化部署DeepResearch
前言
不久前,OpenAI 推出了基于全网权威信源搜索打造的报告生成神器Deep Research ,引发全球关注。
然而,Deep Research月费200美金,性价比并不算高;此外,针对不同任务,各家大模型各有所长,只绑定其中一家最终效果往往并不理想。最重要的是,企业级场景中,真正有价值的数据,比如企业场景中的项目文档、研发的CAD图纸,多以非结构化形式储存在本地。
那么,企业如何把本地数据数据与Deep Research结合,还能灵活地挑选适合自己的大模型?
不久前,我们结合DeepSeek等主流开源模型,并在常见的RAG方案上做了重大升级,推出开源项目Deep Searcher,帮助大家在企业级场景中,基于Deep Research思路,做私有化部署。
一经推出,仅一周时间,该项目已经在Github上收获了800+星和众多关注和讨论,成为备受关注的本地部署企业级DeepResearch方案。
尝鲜链接:https://github.com/zilliztech/deep-searcher
本文中,我们将以硅基流动 + DeepSeek +DeepSearcher为例,为大家带来本地部署展示。
01
为什么说DeepSearcher是搜索AGI的最新RAG范式
事实上,在DeepSearcher出现之前,企业做本地知识检索与专业内容生产的链路,一直是由一个个断点组成。
在Simple RAG时代,我们问题拆解,本地知识检索,互联网知识检索,基于检索的内容生成,是在不同环节被拆解完成的。
到了Graph RAG时代,检索与带有一定推理能力的内容生成成为可能,不过对于如何将问题深度拆解,到底需要检索什么内容,仍处于比较初级的形态。
到了Deep Searcher时代,一方面是模型推理能力的进步,一方面是算力的提升,从提问到问题拆解,到不同内容的检索,到生成,得以在一个环节内执行,RAG完成了从一个工具,到完整解决问题的角色进化。
02
选型参考:硅基流动 + DeepSeek +Milvus=DeepSearcher
本次复现中,我们会采用硅基流动 + DeepSeek +Milvus的方式来打造企业本地的Deep Searcher,选型逻辑如下:
硅基流动
硅基流动致力于打造规模化、标准化、高效能AI Infra 平台,提供高效能、低成本的多品类AI 模型服务,并能提供“满血” 的DeepSeek R1 服务。与此同时,过年前后,在DeepSeek官方入口频繁被挤崩的背景下,硅基流动联合华为昇腾成为国内最早一批将DeepSeek模型部署到自家服务上,并为每个注册用户提供了免费的api key及邀请奖励额度的平台。
(另,新用户注册,平台会送14元免费额度,邀请新用户也可得14元额度)
DeepSeek
DeepSeek是目前全球范围内最顶级的开源大模型企业,旗下Deepseek R1 ,还有DeepSeek V3均处于全球领先水平,在内容生成方面,具备相当优势。
Milvus
相较Open AI的DeepResearch,DeepSearcher最大的优势在于可以接入本地数据与知识库,将企业的本地私有数据应用至复杂的研究任务中。使用开源的Milvus向量数据库,可以对企业的私有化数据进行更加高效管理,使得大模型可以更加准确有效地回答用户疑问。
03
实操教程
第一步:硅基流动准备工作
1.注册硅基流动账号,访问 https://siliconflow.cn/ 进行注册
2.创建API Key,完成后需要保存个人的API Key,文章后续需要使用该Key,另外个人Key注意保密,如果出现泄漏可以删除重新生成。
 2.20-1.png
2.20-1.png
第二步:DeepSearcher运行环境准备
1.从Github上获取项目源码
git clone https://github.com/zilliztech/deep-searcher.git
2.为DeepSearcher创建虚拟python环境,建议使用python3.10以上版本,下面使用python自带的venv创建虚拟环境,也可以根据自己熟悉的工具进行创建。
cd deep-searcherpython3 -m venv .venvsource .venv/bin/activate
3.安装deepsearcher及其依赖第三方库
pip install -e .
第三步:DeepSearcher 示例运行
1.设置环境变量,以下以Linux为例,编辑用户目录下的.bashrc,添加SILICONFLOW_API_KEY环境变量,其值设置为自己的API Key。
export SILICONFLOW_API_KEY=sk-xxx
2.编辑项目DeepSearcher项目下的examples目录下的basic_example.py文件,设置硅基流动的DeepSeek服务。下面示例中设置的是deep seek v3的模型,也可以设置为r1(即:deepseek-ai/DeepSeek-R1),更多模型选项可以参考其官方文档:https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions
config.set_provider_config("llm", "SiliconFlow", {"model": "deepseek-ai/DeepSeek-V3"})
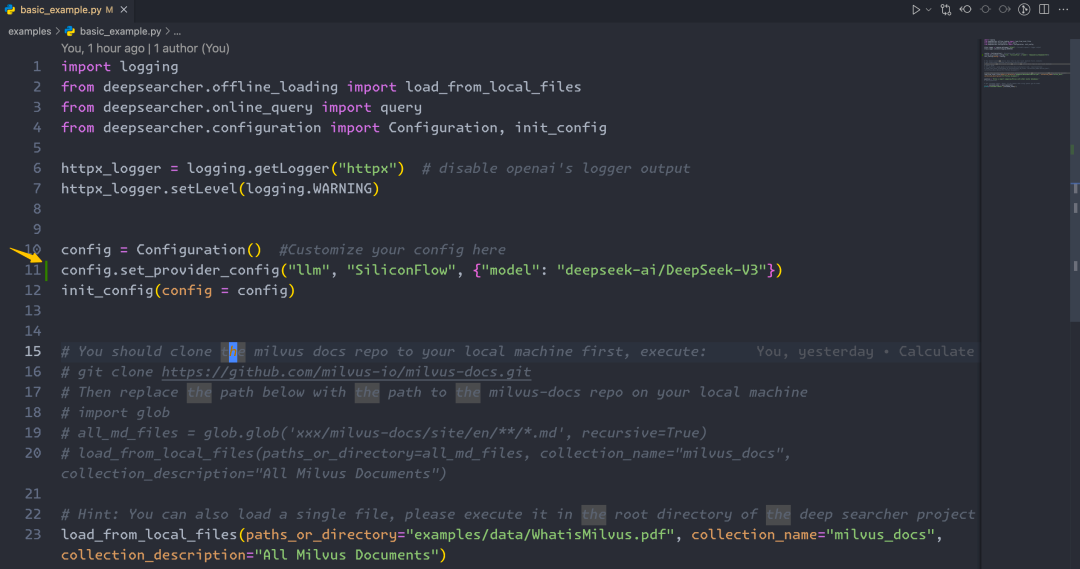
3.在运行前,这里简单介绍下这个示例,是加载一个本地的pdf,然后让大模型针对于这个pdf回答问题,当然你也可以通过同样的方式load更多pdf。这篇文章只是一个简单的示例演示,更多关于DeepSearcher的介绍参考之前发送的文章。
# 确保你在该项目的根目录python examples/basic_example.py
 2.20-3.png
2.20-3.png
运行后,将会看到整个问题思考解答的部分流程,在最后会给出一个类似于下图的最终答案。
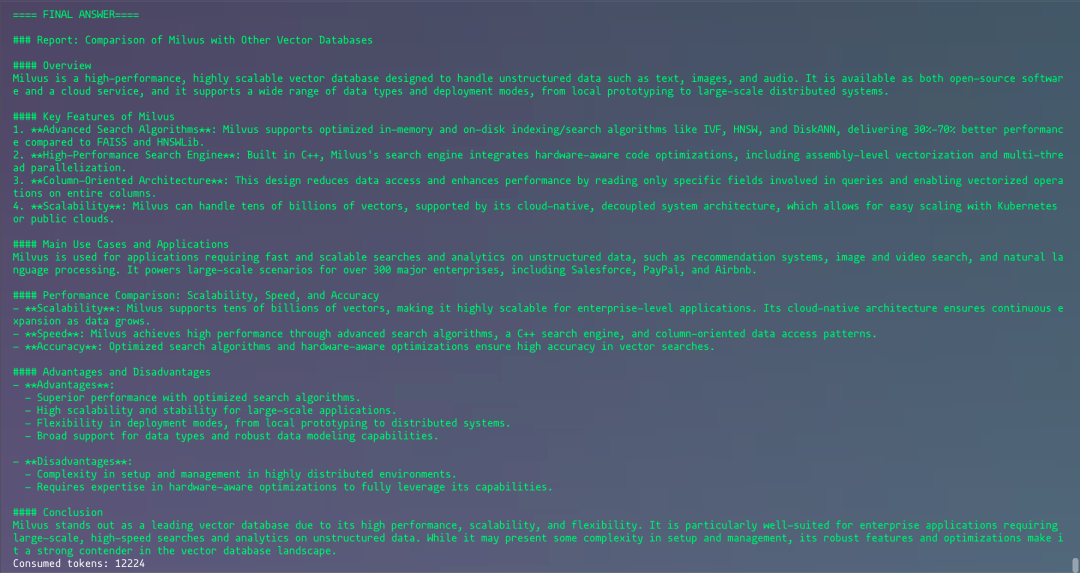 2.20-4.png
2.20-4.png
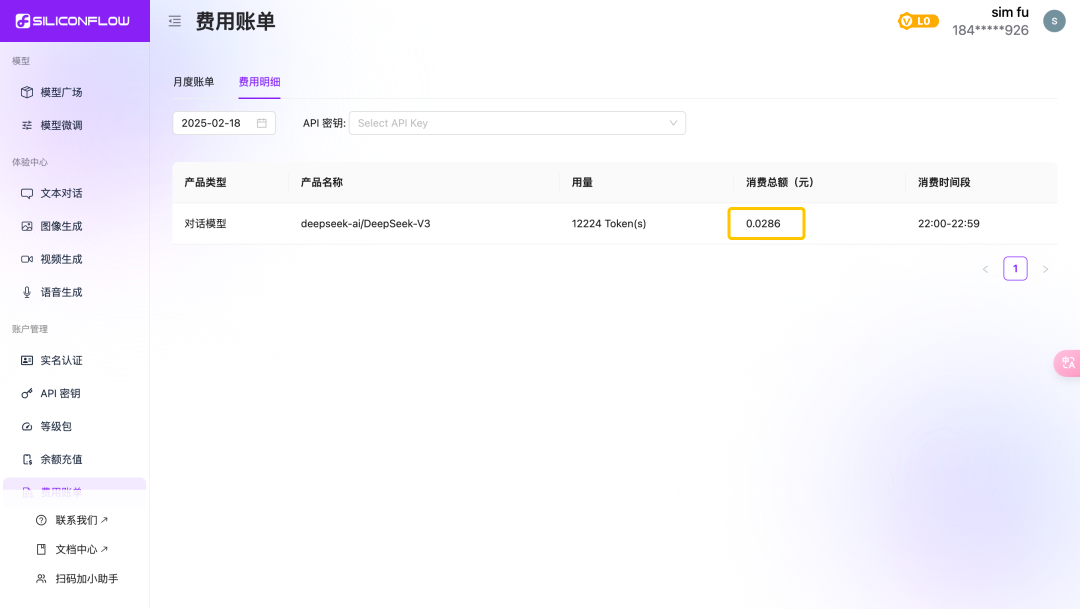
这个示例最后也打印出了消耗的token数目,同时也可以在硅基流动平台查看该次消耗的费用。运行这次示例,笔者消耗了12224 token数目,费用为0.0286元。
 2.20-5.png
2.20-5.png
04
写在最后
目前很多其他云厂商也提供了DeepSeek服务,如阿里云、科大讯飞、腾讯云等,也可以类似的设置,主要就是修改config,因为每个平台其模型名称可能存在差异,另外base url也不一样,可以参照下面示例对应编写。
config.set_provider_config( "llm", "DeepSeek", { "model": "xxx", "api_key": "xxx", "base_url": "xxx", },)
 付邦
付邦