



Milvus week | 官宣:Milvus2.6发布MinHash LSH ,低成本去重百亿文档,加速大模型训练

前言
大型语言模型(LLMs)能力边界扩张的背后是优质数据的支撑,但是当下,大模型的进展已经到了一个瓶颈期。
很多大模型客户都在向我们反馈,其数百亿文档中存在大量重复冗余内容,不仅浪费计算资源,更导致大模型反复“咀嚼”相同的知识,变得“偏食”,在学习新知识时效果不佳。
传统的检索方法在这个数据量级下根本无法扩展,市面上的专用去重工具又消耗过高的计算资源,导致成本上难以承受。
经过深入合作,我们提出了基于 MinHash LSH(局部敏感哈希)的索引方案,并将其集成到了 Milvus 2.6 中。在本文中,我们将介绍 MinHash LSH 是如何高效解决 LLM 训练中的数据去重难题的。
01
数据去重:LLM 预训练的关键挑战
高质量、多样化的数据是训练强大 LLM 的基石。而重复内容会引发一系列严重问题:
资源浪费:冗余数据会显著增加训练时间、成本和能耗;
性能下降:模型容易在重复内容上过拟合,降低了对新信息的泛化能力;
加剧记忆效应:重复内容提升了模型逐字复现文本的概率,可能引发隐私泄露或版权问题;
评估失真:如果训练集与测试集中存在重复,模型的评估指标可能被意外“灌水”。
数据去重并非简单的“查找替换”。根据重复的粒度,它可以分为不同层面,例如文档级别、句子级别乃至更细的 token 级别。实践证明,综合运用这些不同层面的去重策略,才能更有效地提升 LLM 的训练效果。
目前主流的去重方法可以分为三类:
精确匹配:通过对整个文件或者数据块进行哈希计算,找出完全相同的文本;
近似匹配:使用如 MinHash LSH、Jaccard 相似度等算法找出“相似但不完全相同”的文本;
语义匹配:用深度学习模型(如 Transformer)将文本转换为向量嵌入(Embeddings),然后在向量空间中通过聚类或计算余弦相似度等方法,找出那些在语义层面表达相同或相似思想的文本。
随着预训练语料体量达到 TB 甚至 PB 级别,传统的精确匹配(如两两比对)根本无法承载计算负载,而语义去重则涉及向量生成和大规模匹配,开销巨大。
因此,我们需要一种高效又精准的近似匹配方法,既能控制成本,又能兼顾召回率和准确率 —— MinHash LSH 正是理想的选择。
02
MinHash LSH:大海捞针的智能快捷键
想在汪洋般的训练数据中找出相似文档,我们需要一种既高效又可靠的近似匹配算法。MinHash LSH(局部敏感哈希)是为此目标设计的利器。我们来一步一步拆解这个听起来略显复杂的术语。
步骤一:使用 MinHash 表征文档
在衡量文档之间的相似度时,我们常用的指标是 Jaccard 相似度:
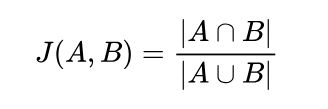
它表示两个集合交集元素数量与并集元素数量之比,数值越高表示越相似。
但要直接计算大规模文档集合中每对文档的 Jaccard 相似度,计算成本极高。MinHash 可以通过压缩原始集合为固定长度的签名向量,近似估算 Jaccard 相似度,从而大幅降低计算开销。
整体过程大致如下:
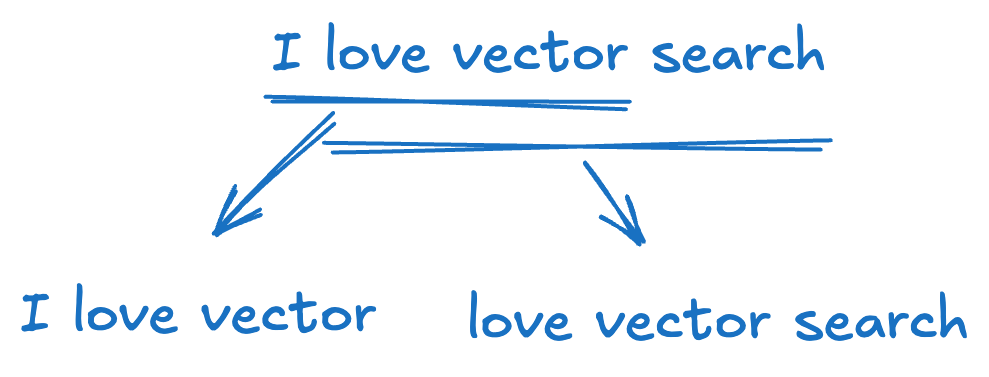
1. Shingling(切片处理):将每个文档拆分成由单词或字符构成的短语切片集合(称为 k-shingles)。 例如,句子 “I love vector search”,按词进行切片,k=3 时会得到以下切片集合: {“I love vector”, “love vector search”}。
2. MinHashing(最小哈希) :对每个文档的切片集合应用多个哈希函数,并记录每个函数作用后得到的最小哈希值。这样可以为每个文档生成一个签名向量(signature vector)。

在计算相似度时,两个文档的 MinHash 签名中相同位置的哈希值一致的概率(对应于这些签名的 Jaccard 距离),可以很好地拟合原始切片集合之间的 Jaccard 相似度。这使我们能够在不直接比对原始长文本的情况下,借助紧凑的 MinHash 签名有效地估算文档相似性。
MinHash 的原理是:通过多个哈希函数提取每个文档切片集合中哈希值最小的元素,作为文档特征的一部分。这样可以用固定长度的签名向量代表整个文档,并通过引入多个哈希函数来提升准确性。细微的单词变化通常不会影响最小哈希值,因此可能被忽略;而更显著的改动更容易改变哈希值,从而被检测出来。这个过程可以理解为对所有单词的哈希值进行“最小池化”(min-pooling)。
除了 MinHash 之外,还有其他方法如 SimHash 可用于生成文档签名,但此处不做展开。
步骤 二:通过 LSH 快速“配对”相似“草图”
即使使用了紧凑的 MinHash 签名,在数百万甚至数十亿个文档中进行两两比对,计算成本依然非常高。此时就需要引入 局部敏感哈希(Locality Sensitive Hashing, LSH)。
LSH 的核心思想是:使用一种特殊的哈希函数,让相似的项更可能落入同一个桶(bucket),而不相似的项则不会。这与传统哈希算法追求避免碰撞的目标正好相反。
针对 MinHash,常见的 LSH 策略是 banding(分条带法)技术:
分条带(Banding):将每个 MinHash 签名(长度为 N 的向量)划分为b个带(band),每个带包含 r维(即 N = b × r)。
条带哈希(Hashing Bands):对每个带(r 个哈希值组成的子向量)使用标准哈希函数将其哈希到某个桶中。
候选配对(Candidate Pairs):如果两个文档的任意一个条带落入同一个桶,即被标记为可能相似。
通过调整带数b和每带的维数r,可以在召回率(找到所有相似对)、精确率(减少误报)和速度之间进行权衡。通常来说:高度相似的文档往往有很多相同的哈希值,因此至少在某一带中落入同一个桶的概率更高。
简而言之,MinHash + LSH 提供了一种兼顾效率与效果的近似去重策略,适用于百亿级语料下的预处理优化:MinHash 通过将文档压缩为签名,LSH 高效缩小搜索空间,快速定位潜在重复对。 可以形象地理解为在人群中识别双胞胎: 先给每个人拍一张特征照(MinHash)、再按相似脸分组(LSH)、最后只检查这些小组成员是否真的一模一样。
03
Milvus 2.6 对 MinHash LSH 的支持
将 MinHash LSH 集成进 Milvus 2.6,是源于真实的业务需求。正如前文提到的,一家全球领先的大模型公司向我们提出了需求:如何高效地对用于大模型预训练的海量文本数据进行去重。传统的去重流程通常依赖于存储系统之外的外部工具,数据需要在多个模块之间频繁转移,代价高昂。这种割裂的处理方式不仅增加了运维负担,还难以充分利用分布式计算资源。
而 Milvus 天生擅长处理高吞吐量的向量数据,因此我们自然想到:
如果把 MinHash LSH 原生构建在 Milvus 中,把近似去重变成数据库的基础能力,会怎样?
这一设计思路让整个流程从数据去重到语义检索都可以在 Milvus 内部完成,大幅简化了 MLOps,同时充分利用其可扩展架构与统一 API 接口。
有了这个思路,我们与合作伙伴共同对 MinHash LSH 进行了深度优化,使其在 Milvus 的云原生架构中具备了快速、可扩展的去重能力。
Milvus 2.6 中的核心功能包括:
原生 MinHash LSH 索引:实现了标准的 banding(条带划分)策略,并支持可选的 Jaccard 重排序以提升召回率。同时提供内存版和基于 mmap 的索引实现,以适配不同的工作负载场景。
无缝 API 集成:用户可以通过标准 SDK 或声明式 API 定义 MinHash 类型的向量字段,构建 MINHASH_LSH 索引,插入签名向量,并执行近似相似性搜索。
分布式 & 可扩展:依托 Milvus 的云原生架构,该功能支持水平扩展,适用于大规模数据集与高并发处理场景。
这项集成在实际中取得了令人瞩目的成果。我们在全托管的 Milvus(Zilliz Cloud)上运行 MinHash LSH,帮助该用户高效完成了100 亿级文档的去重。相比他们原先基于 MapReduce 的方案,新的架构在处理速度上提升超过 2 倍,并在成本上实现了 3–5 倍的优化。我们不仅为合作伙伴解决了燃眉之急,也为 Milvus 社区贡献了一项极具价值的新功能。
04
实战:使用 Milvus 进行大模型训练数据去重
说完理论,现在让我们亲手体验,如何在 Milvus 2.6 中通过 MinHash LSH 进行大规模的近似去重。
前提: 生成 MinHash 签名向量
Milvus 负责对预先生成的 MinHash 签名进行索引与搜索。你需要在预处理阶段借助 Python 的 datasketch 等工具,或使用自定义代码来生成这些签名。
典型的处理步骤如下:
读取原始文档;
对每个文档进行切片处理(shingle),即按词或字符进行分片;
对分片集合应用多个哈希函数,生成 MinHash 签名(例如,长度为 128 的 uint64 整数数组)。
接下来,就可以将这些签名向量导入 Milvus,构建索引,并进行高效的近似去重查询
步骤 1:在 Milvus 中创建一个集合(Collection)
我们需要在 Milvus 中创建一个集合,用于存储 MinHash 签名及其对应的文档 ID。
from pymilvus import connections, Collection, FieldSchema, DataType, CollectionSchema, utility
import numpy as np # Required import
import random # Required import
# Milvus server address and port
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
# Collection name
COLLECTION_NAME = "llm_data_dedup_minhash"
# Dimension of MinHash signatures (e.g., using 128 hash functions)
MINHASH_DIM = 128
MINHASH_BIT_WIDTH = 64 # Assuming 64-bit hash values
# Connect to Milvus
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
# Define fields
# Primary key field, storing the unique ID of the document
doc_id_field = FieldSchema(name="doc_id", dtype=DataType.INT64, is_primary=True, auto_id=False)
# MinHash signature field
minhash_signature_field = FieldSchema(name="minhash_signature", dtype=DataType.BINARY_VECTOR, dim=MINHASH_DIM * MINHASH_BIT_WIDTH) # MinHash vectors are input as binary vectors, dim = hash_value_bit_width * hash_vector_dimension
schema = CollectionSchema(fields=[doc_id_field, minhash_signature_field],
description="Collection for LLM data deduplication using MinHash")
print(f"Schema defined for collection: {COLLECTION_NAME}")
# If the collection already exists, delete it first
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
collection = Collection(COLLECTION_NAME, schema=schema)
print(f"Collection {COLLECTION_NAME} created.")
步骤 2:创建 MINHASH_LSH 索引
这是核心步骤。我们需要将相似度度量类型设置为 JACCARD,并配置与 LSH 相关的参数。
# Index parameters
INDEX_FIELD_NAME = "minhash_signature"
# Metric type, should be JACCARD for MinHash LSH
METRIC_TYPE = "MHJACCARD"
INDEX_TYPE = "MINHASH_LSH"
index_params = {
"metric_type": METRIC_TYPE,
"index_type": INDEX_TYPE,
"params": {
# LSH-specific parameters might be configured here, e.g.:
# "num_bands": 20, # Hypothetical parameter: number of bands
# "element_bit_width": MINHASH_BIT_WIDTH # Bit width of minhash values
# The specific names and availability of these parameters depend on Milvus 2.6's implementation.
}
}
# Create index on the minhash_signature field
print(f"Creating index {INDEX_TYPE} on field {INDEX_FIELD_NAME} with metric {METRIC_TYPE}...")
collection.create_index(field_name=INDEX_FIELD_NAME, index_params=index_params)
print("Index creation request sent.")
# Load the collection into memory for searching
print(f"Loading collection {COLLECTION_NAME}...")
collection.load()
print("Collection loaded.")
关于参数调优的说明: MinHash LSH 的效果在很大程度上依赖于参数的选择。例如,在生成 MinHash 签名时使用的哈希函数数量(即 MINHASH_DIM)会影响签名的精度和长度。在 LSH 阶段,条带的数量(num_bands)和每个条带的维数共同决定了相似度阈值的敏感区间,以及召回率与精确率之间的平衡。 用户需要根据自己的数据特点和去重需求进行实验和微调。这通常是一个反复迭代的过程。
步骤 3:插入 MinHash 签名数据
假设你已经有了一批文档及其对应的 MinHash 签名,现在可以将这些数据插入 Milvus。**
# Sample data: doc_ids and corresponding MinHash signatures
num_entities = 100
doc_ids_to_insert = [i for i in range(num_entities)]
# Generate illustrative "MinHash signatures" (list of byte strings)
# Each signature is MINHASH_DIM * (MINHASH_BIT_WIDTH / 8) bytes long
minhash_signatures_to_insert = []
for _ in range(num_entities):
# Create a random numpy array of uint64 integers
# Each uint64 is 8 bytes. We need MINHASH_DIM such integers.
random_signature_array = np.random.randint(0, 2**MINHASH_BIT_WIDTH, size=MINHASH_DIM, dtype=np.uint64)
minhash_signatures_to_insert.append(random_signature_array.tobytes())
entities_to_insert = [
doc_ids_to_insert,
minhash_signatures_to_insert
]
# Insert data
insert_result = collection.insert(entities_to_insert)
collection.flush() # Ensure data is written to persistent storage
print(f"Inserted {len(insert_result.primary_keys)} entities.")
print(f"Number of entities in collection after insert: {collection.num_entities}")
步骤 4:搜索近似重复文档
使用某个文档的 MinHash 签名,在集合中检索与之相似的文档。**
# Assume we want to query for similar items to the first document's signature
query_minhash_signature_bytes = [minhash_signatures_to_insert[0]] # Must be a list of byte strings
# Search parameters
# For MINHASH_LSH, search parameters might include top_k or a similarity threshold/distance range.
# This depends on Milvus 2.6's specific implementation.
search_params_lsh = {
# "reordered_k": 100, # If searching with reordered_k, MINHASH_LSH will use as a refiner, Milvus will return jaccard.
}
print(f"\nSearching for near-duplicates of a sample signature...")
# anns_field is the field where we created the index
# limit is the number of results to return
results = collection.search(
data=query_minhash_signature_bytes, # Query data (list of byte strings)
anns_field=INDEX_FIELD_NAME,
param={"metric_type": METRIC_TYPE, "params": search_params_lsh}, # metric_type should also be in param
limit=10, # Find the top 10 most similar items (including itself)
expr=None, # Can add filter expressions, e.g., "doc_id != query_doc_id"
consistency_level="Strong"
)
# Process search results
print("\nSearch results (candidate near-duplicates):")
if results:
for hits in results:
for hit in hits:
# hit.id is the doc_id of the similar document
# hit.distance is the Jaccard distance (smaller is more similar) or some LSH score
print(f" Doc ID: {hit.id}, Distance/Score: {hit.distance:.4f}")
else:
print("No results found or an error occurred during search.")
步骤 5:后处理与聚类
检索返回的结果是候选的近似重复文档。
你需要根据返回的 Jaccard 距离(或 LSH 评分)来判断它们是否真的构成重复。通常会设定一个阈值,例如 Jaccard 距离小于 0.2(即 Jaccard 相似度大于 0.8)的视为重复。
得到这些候选的相似对之后,为了形成完整的去重分组,可以对这些候选对应用聚类算法,例如 并查集(Union-Find)。每个集合结果代表一组重复文档;保留其中一份作为代表文档,其余的可以归档或删除。
结语
不仅仅是去重
Milvus 2.6 中引入的 MinHash LSH,是 AI 数据处理的一次重大飞跃。最初,它是为了解决大模型训练数据去重问题而设计的,如今却打开了更多应用场景的大门——如网页内容清洗、商品目录管理、抄袭检测等。
如果你也有类似的需求,欢迎加入 Milvus 的 Discord 社区,与我们预约 Office Hour,一对一深入交流。
让我们一起构建更智能的 AI 基础设施。



