



查询响应变慢,应该甩锅给谁?怎么解决?|Milvus干货课堂
本来大模型回答问题就已经够慢了,结果做了个RAG,系统在检索环节又花了两三秒,相信这应该是不少人的噩梦。
更别提在电商之类的搜广推场景,面对即将到来的双十一
用户刚看完一个沙滩泳衣,你要是不能在0.1秒的时间里给对方推送出一个高倍数防晒霜
公司业务下滑的锅,就要稳稳的扣在技术团队的头上。
 14.webp
14.webp
那么慢查询到底是如何发生的?要如何解决慢查询问题?又该如何避免慢查询的出现?本文将一一解答。
01 识别慢查询
排查慢查询的第一步是发现问题,分析时间都花在哪里了。Milvus 可以通过指标和日志来实现这两点。
- Milvus 指标(Milvus Metrics :https://milvus.io/docs/monitor_overview.md):可以通过 Grafana 的仪表盘面板查看和分析 Milvus 的各项指标。
 14-2-1.webp
14-2-1.webp
 14-2-2.webp
14-2-2.webp
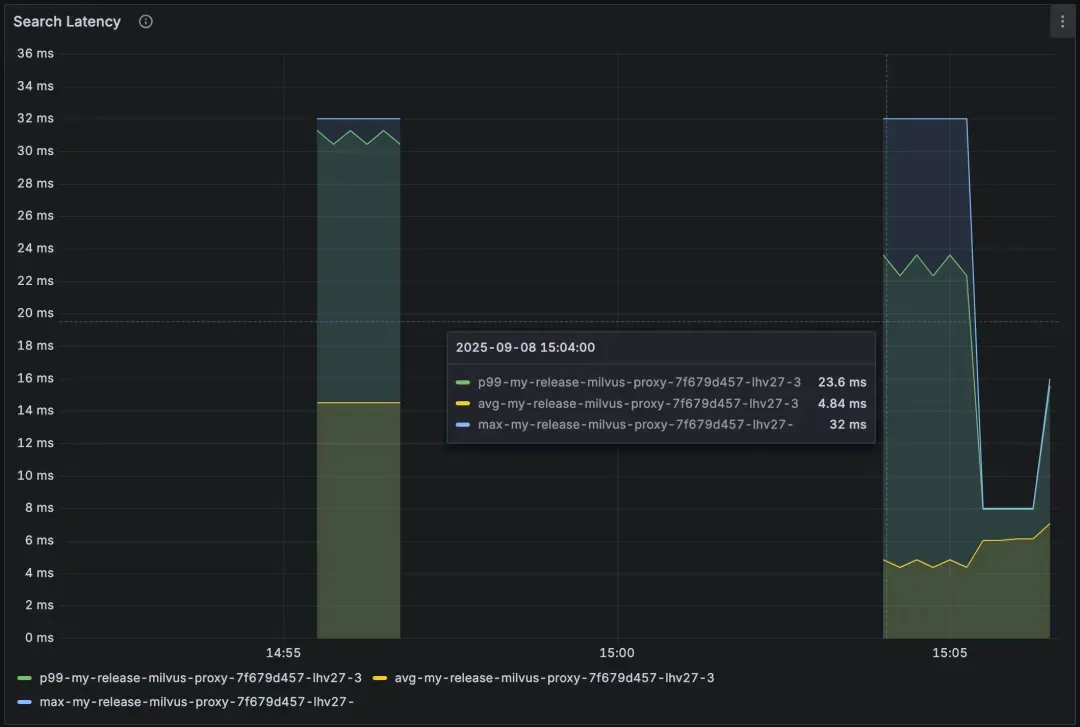
当搜索延迟超过 proxy.slowQuerySpanInSeconds(https://milvus.io/docs/configure_proxy.md#proxyslowQuerySpanInSeconds)(默认值:5秒)时,Milvus 会在 Prometheus 中标记该请求为慢搜索,并出现在面板 Service Quality -> Slow Query 中。
Service Quality -> Search Latency 可以查看整体延迟情况。如果这里看起来正常,但客户端仍然反馈延迟,那问题可能出在网络或应用层。
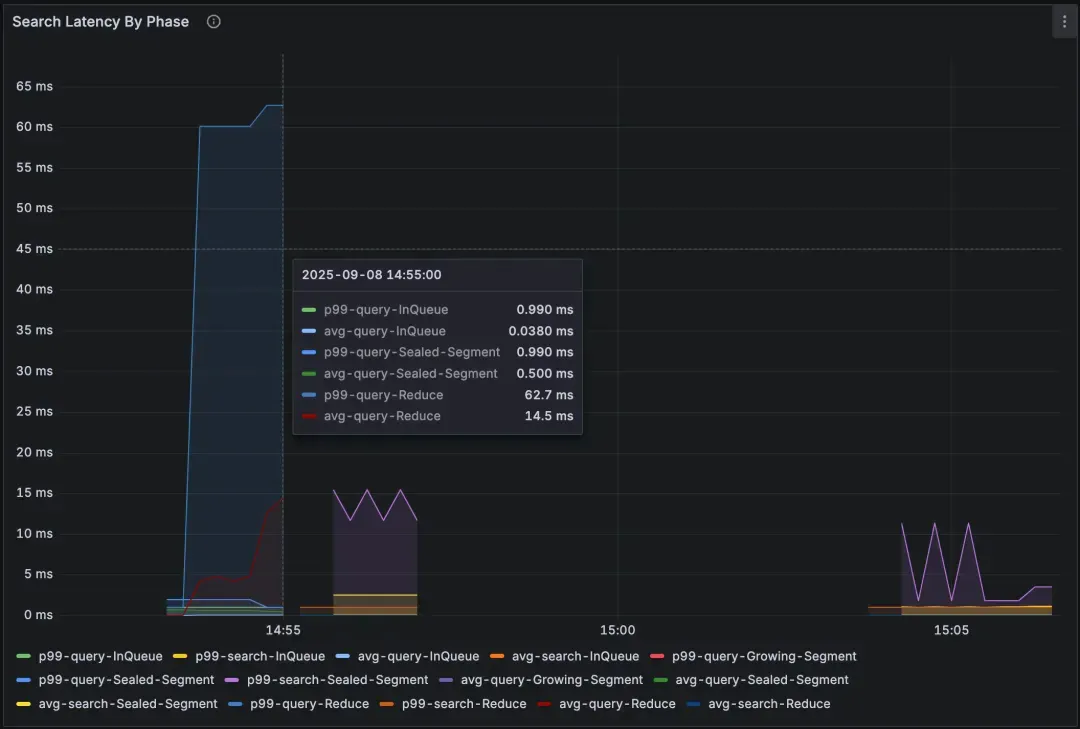
Query Node → Search Latency by Phase 提供了一个包含了排队、查询、归并等情况的高级视图。想要做更深入的归因,可以在 Scalar Filter Latency, Vector Search Latency 和 Wait tSafe Latency 等面板查看哪个阶段影响最大。
Milvus 日志(https://milvus.io/docs/configure_grafana_loki.md):任何持续超过 1 秒的请求都会自动记录为慢查询,并附有诸如 ["Search slow"] 的标记。一般来说:
大多数情况下,搜索延迟应 < 30 毫秒
延迟 > 100 毫秒就需要关注一下了。
延迟 > 1 秒 则肯定是慢速查询,需要重点排查。
参考日志:
[2025/08/23 19:22:19.900 +00:00] [INFO] [proxy/impl.go:3141] ["Search slow"] [traceID=9100b3092108604716f1472e4c7d54e4] [role=proxy] [db=default] [collection=my_repos] [partitions="[]"] [dsl="user == \"milvus-io\" && repo == \"proxy.slowQuerySpanInSeconds\""] [len(PlaceholderGroup)=8204] [OutputFields="[user,repo,path,descripion]"] [search_params="[{\"key\":\"topk\",\"value\":\"10\"},{\"key\":\"metric_type\",\"value\":\"COSINE\"},{\"key\":\"anns_field\",\"value\":\"vector\"},{\"key\":\"params\",\"value\":\"{\\\"nprobe\\\":256,\\\"metric_type\\\":\\\"COSINE\\\"}\"}]"] [ConsistencyLevel=Strong] [useDefaultConsistency=true] [guarantee_timestamp=460318735832711168] [nq=1] [duration=5m12.002784545s] [durationPerNq=5m12.002784545s]
可以看到,指标能帮你定位耗时环节,日志则能明确哪些查询出了问题。
02 慢查询出现的常见原因
(1)工作负载过高
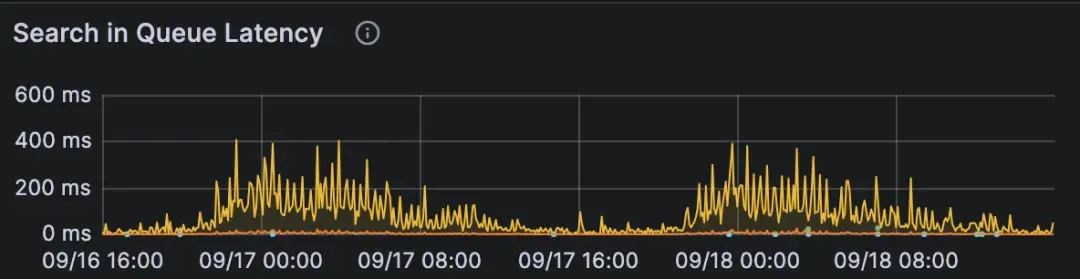
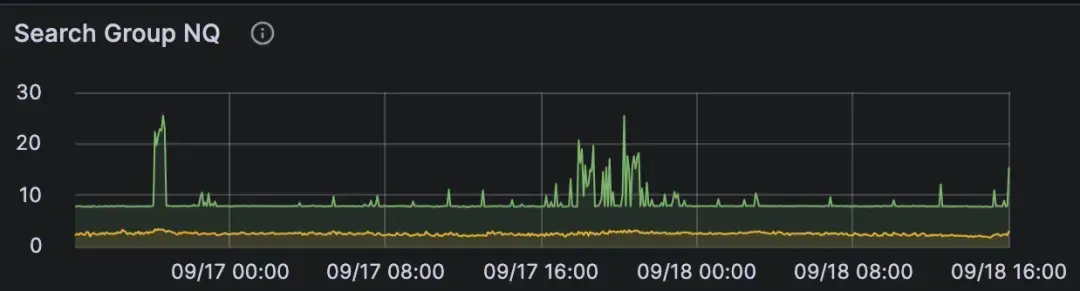
当一个请求携带非常大的 NQ(每个请求的查询数据数量)时,它会运行很长时间并占用查询节点资源。其他请求排队等待,从而导致队列延迟上升。哪怕此时你的nq 很小,但只要总体查询量(QPS)位于高位,结果也是一样的,因为Milvus 可能会内部合并并发搜索请求。
 14-2-3.webp
14-2-3.webp
 14-2-4.webp
14-2-4.webp
表现:
所有查询的延迟都很长。
查询节点的队列延迟在上升。
日志显示 nq 很大,总耗时长,但单个查询耗时短,说明个别请求占用了太多资源。
解决方案:
通过批量查询控制 nq 的大小。
如果高并发是常态,可以考虑扩展Query Node。
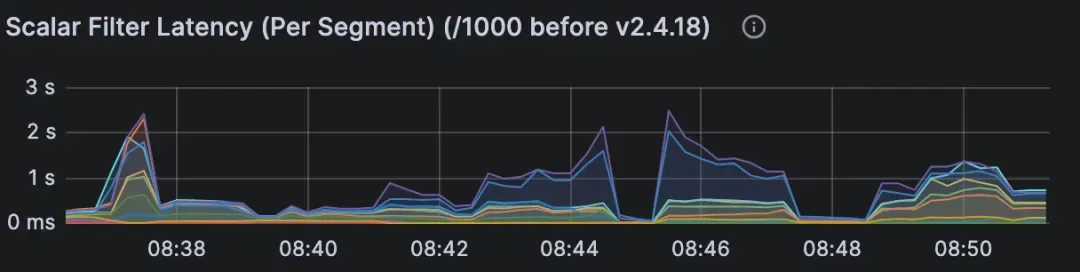
(2)过滤方式低效
使用不合适的表达式进行过滤,或者没有标量索引,可能会导致全表扫描,而不是高效的子集扫描。另外,JSON 过滤器和强一致性会增加额外的开销。
 14-2-5.webp
14-2-5.webp
 14-2-6.webp
14-2-6.webp
表现:
查询节点的标量过滤延迟很高。
使用过滤器时搜索延迟明显增加。
如果启用了强一致性,等待 tSafe 的延迟会较长。
解决方案:
优化过滤表达式以减少查询计划的复杂性。例如,使用模板(https://milvus.io/docs/filtering-templating.md)构建过滤表达式以减少解析成本。
把多个 OR 条件用 IN 替换掉
# Replace chains of OR conditions with IN
tag = {"tag": ["A", "B", "C", "D"]}
filter_expr = "tag IN {tag}"
为过滤字段添加合适的索引,避免全表扫描。
对于 JSON 字段,Milvus 2.6 引入了path and flat index,未来版本还会支持 JSON shredding。
如果不需要严格一致性,可以调整一致性级别(使用
Bounded或者Eventually)。
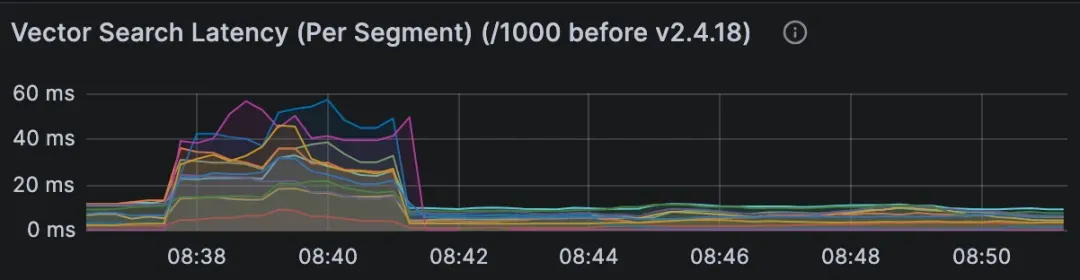
(3)向量索引选择不当
选择错误的索引会严重影响延迟。具体来说,针对常见的向量类型:内存型索引速度最快,但占用大量内存;磁盘型索引节省内存,但会牺牲性能;二进制向量则需要专门的索引。
 14-2-7.webp
14-2-7.webp
表现:
查询节点指标中向量搜索延迟很高。
使用 DiskANN 或启用 MMAP 时,搜索期间磁盘 I/O 饱和。
重启后查询变慢(缓存冷启动)。
解决方案:
根据工作负载为浮点向量选择合适的索引,通常来说:
HNSW:内存索引,低延迟,高召回率。
IVF 索引:可以灵活调整性能和资源占用。
DiskANN:适合大规模数据,但需要足够的磁盘带宽。
对于二进制向量,Milvus 2.6 引入了 MINHASH_LSH 索引,结合 MHJACCARD 度量,能高效估算 Jaccard 相似性。
启用 MMAP,把索引文件映射到内存,平衡延迟和内存占用。
调整索引或搜索参数,平衡召回率和延迟。
重启后预热常用数据段,避免冷启动带来的延迟。
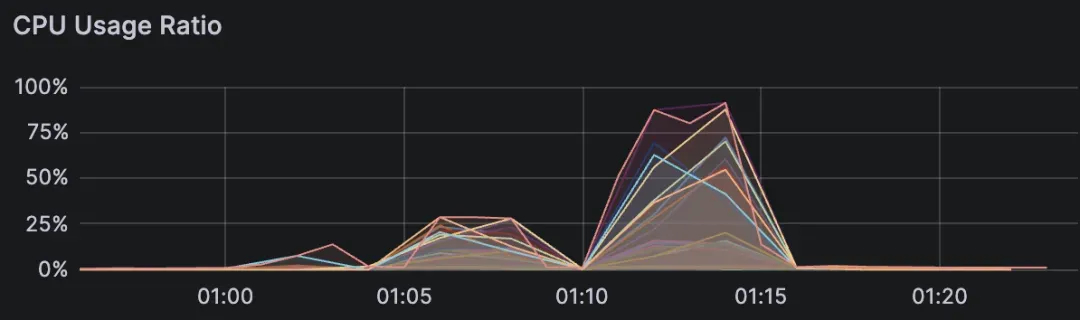
(4)版本选择与系统状态
并非所有慢查询都是查询本身的问题导致的。查询节点和后台任务(比如数据合并和迁移)共享资源。频繁的 upsert 操作会产生大量未索引的小片段数据,导致搜索需要扫描原始数据。某些版本的性能问题也可能导致延迟增加。
 14-2-8.webp
14-2-8.webp
信号:
在后台任务期间 CPU 使用率激增。
影响查询节点的磁盘 I/O 饱和。
重启后缓存冷启动非常慢。
大量小的未索引数据片段(频繁 upsert 操作)。
与特定 Milvus 版本相关的延迟回退问题。
解决方法:
将数据压缩等后台任务重新安排到非高峰时段。
在可能的情况下释放暂不需要使用的集合以释放内存。
监控集群健康状况,并注意重启后的预热状态。
避免连续发出过多的 upsert 操作;尽可能批量操作,以便压缩能够跟上。
升级以从新版本中的错误修复和优化中受益。
为延迟敏感的工作负载分配额外资源。
03 预防慢查询的最佳实践
解决问题最好的办法是提前预防,避免出现慢查询。以下是五步走经验:
合理分配资源,避免 CPU 和磁盘争用。
设置主动告警,监控延迟和故障。
保持过滤表达式简单且简短
批量处理检索任务,控制 NQ 和 QPS。
为过滤字段创建索引。
做好以上五步走,相信大部分慢查询的问题都能被很好的预防与解决。如果仍有更多疑问,欢迎在评论区留言沟通~
 顾梦佳
顾梦佳


