



Milvus 落地顶级汽车资讯平台:如何支撑易车上亿用户的搜车需求?
通过混合检索模式,将 “ES+语义” 的双层架构简化为一个Milvus架构
但近些年来,当用户逐渐习惯用自然语言表达模糊需求时,多数检索系统还是基于关键词匹配的老一套,已经彻底不够用了。
借助向量数据库实现智能语义检索,成为必选项。
但选谁?选好了要怎么用?要怎么用出成果,对于一个拥有1.42亿月活的汽车类APP却并不容易。
作为AI检索落地的典型代表,易车用了三年时间,从开始接触Milvus,到把Milvus上线核心业务,再到用深Milvus。
他们的故事,或许可以为很多做客服AI、智能检索的企业带来一定的参考与经验。
01
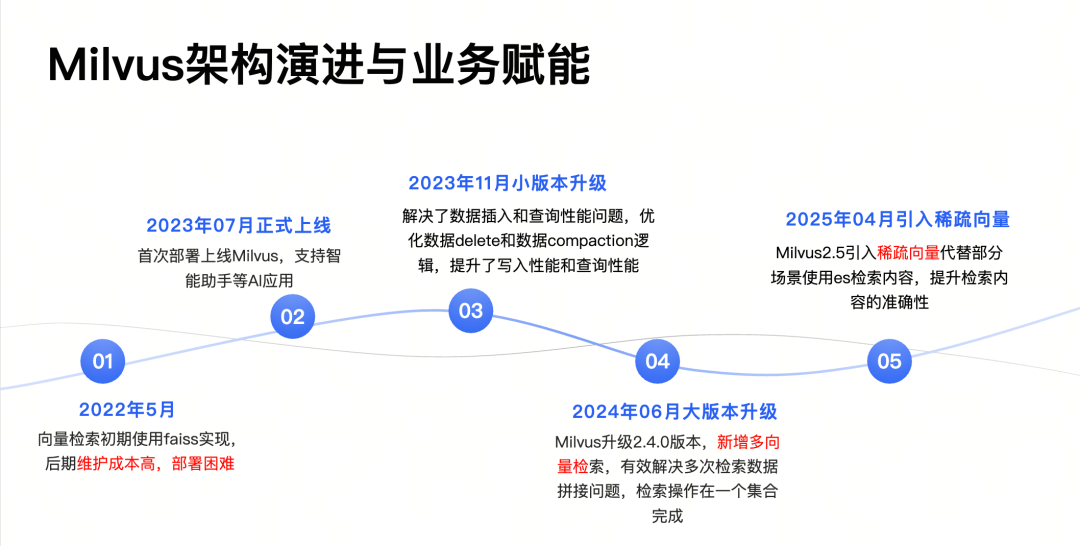
2022 年:Faiss 试水
2022年前后,易车 AI 助手的早期规划中,技术路径选择充满了互联网行业的快试错基因。
这一时期,易车面临的核心困境在于:用户习惯用自然语言表达模糊需求时,但系统还是基于关键词匹配的老一套,已经彻底不够用了。
比如,用户输入想要宽敞的多功能车后,系统反复推送一些关键词类似,但实际结果毫不相关的内容,而后台数据显示,平台上正躺着上百款“大空间SUV”的详细资料。更有甚者,用户需求升级为20万内家用SUV,油耗比CR-V低,隔音要好这类复合需求,可能得到的结果只有系统反复返回“未找到相关结果”
这时候目标很明确,检索需要具备用户模糊需求与精准答案匹配的能力。为了快速验证语义检索的可行性,团队将核心检索逻辑搭建在Faiss 架构上,快速拼接出索引构建、查询与存储的基础流程。
在用户量不足10万的内测阶段,Faiss这套方案表现尚可:至少能解决“大空间SUV”与“宽敞车”的语义关联问题,准确率虽只有45%,但相比传统关键词检索已是质的飞跃。
但随着 AI 助手用户量增长,Faiss 的弊端逐渐暴露。它更像一个临时拼凑的过渡算法库方案:没有完整的系统支撑,索引构建、存储管理都需要大量定制化开发。
团队每天要花半天甚至一两天时间处理非核心业务:为不同场景定制索引存储逻辑、排查跨环境部署的兼容问题。
维护成本居高不下不说,更关键的是,它的扩展性极差,当用户咨询量激增时,查询响应延迟飙升,需要在流量高峰时手动扩容节点,完全无法支撑 AI 助手的规模化推广。
“Faiss 只能解决‘有没有’的问题,解决不了‘好不好’的问题。” 这是团队在 2022 年底的共识 —— 要实现语义检索的规模化落地,必须寻找更成熟、更具扩展性的技术方案。
02
2023 年:Milvus 开源版落地,攻克读写性能瓶颈
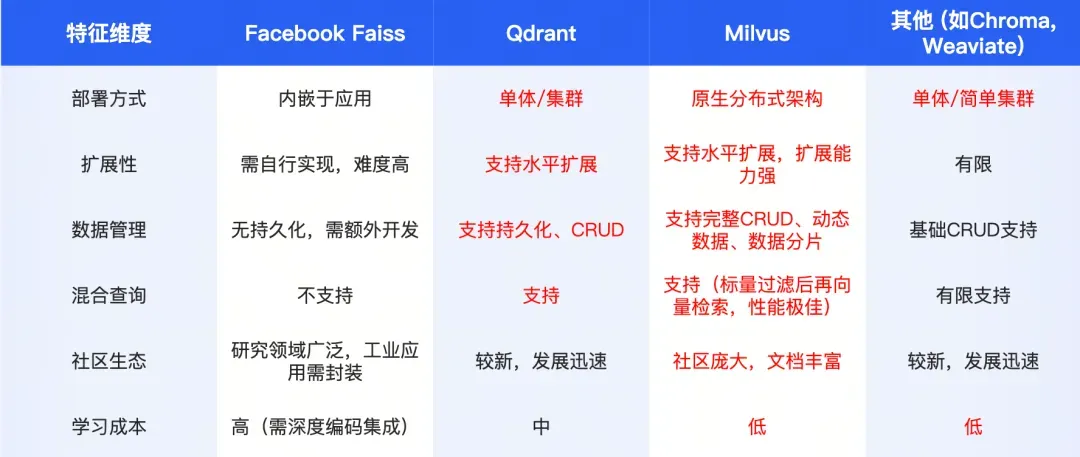
经过多维度选型对比,Milvus 成为易车的最终选择。它的分布式架构、水平扩展能力,以及开箱即用的特性,完美契合 AI 助手的规模化需求。
 640.webp
640.webp
2023 年,易车正式部署开源版 Milvus,将 AI 助手的核心检索场景(车型配置查询、口碑检索、FAQ 问答等)全部迁移至 Milvus 集群。
上线初期,Milvus 的表现一度大超出预期:语义检索准确率大幅提升,“大空间 SUV” 与 “宽敞多功能车” 这类近义词需求能精准匹配;分布式架构支撑起百万级日查询量,响应延迟稳定在毫秒级。
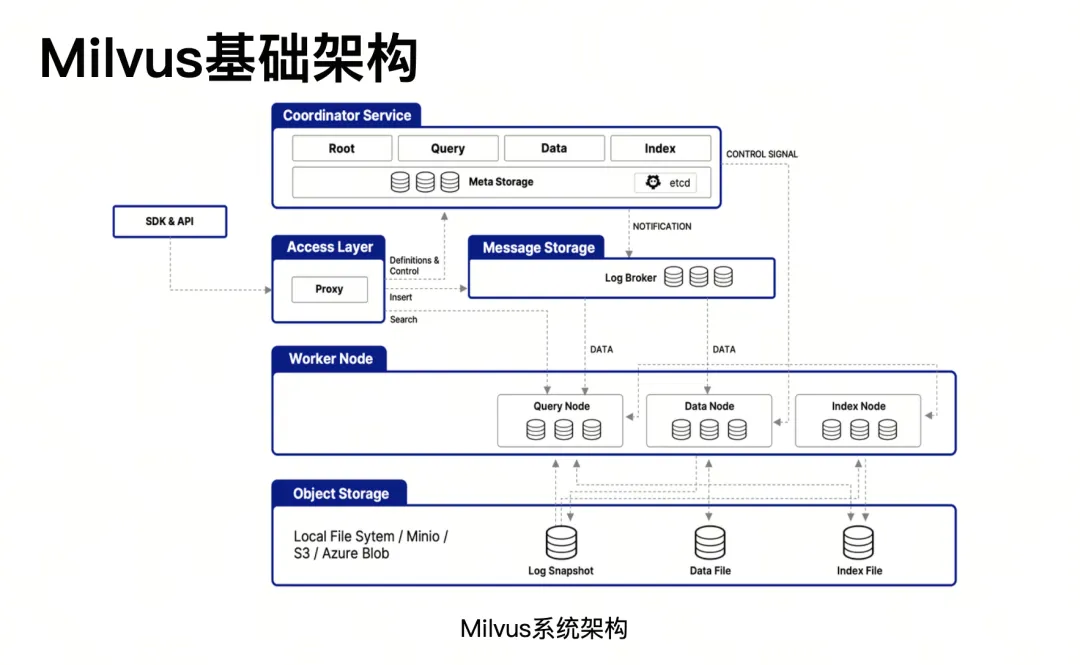
在这背后Milvus的云原生架构是这场突破的关键。其核心采用计算与存储分离设计,Proxy作为集群入口统一分发请求,协同服务节点统筹全局,worker节点分工处理查询、数据初始化和索引构建,底层兼容minIO、S3等多种存储服务。这种架构就像可伸缩的积木,业务高峰时新增query node就能提升吞吐量,数据量增长时扩充data node即可缓解压力,彻底解决了FAAS时代的扩容难题。
 640-1.webp
640-1.webp
但随着数据量突破千万级,新的问题出现了:数据插入和删除效率偏低,批量更新知识库时,集群负载过高,偶尔还会影响正常查询服务。
针对这一痛点,团队在 2023 年 11 月推动 Milvus 小版本升级,重点优化数据删除(delete)和压缩(compression)逻辑。
升级后的效果立竿见影:批量删除响应时间从秒级压缩至毫秒级,数据写入速度提升让 Milvus 真正适配了易车海量数据 + 高频更新的业务场景。
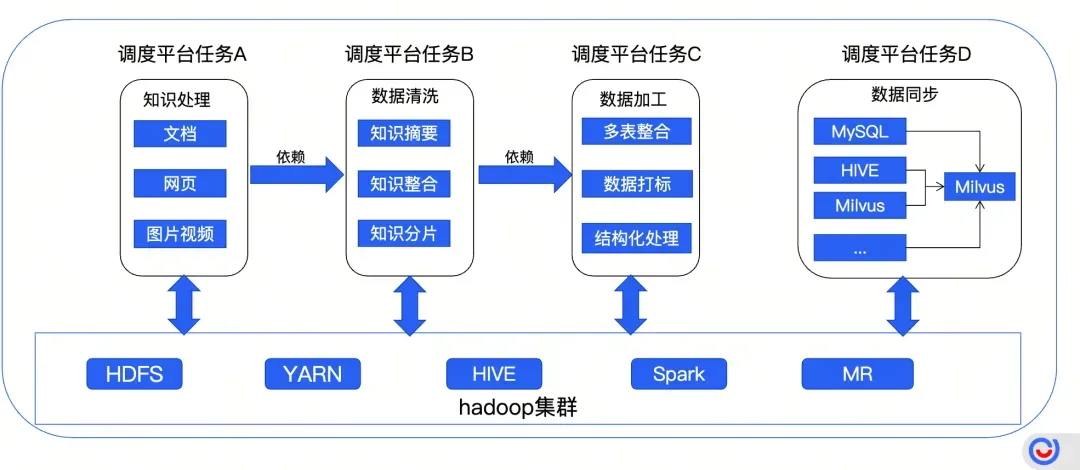
更重要的是,团队还同步搭建了企业级向量数据流水线,将文档、网页、图片等多源数据的清洗、加工、向量化封装成自动化任务,不仅保障了数据逻辑的一致性,还能充分利用大数据集群资源,提升数据处理效率,为 Milvus 提供了高质量的向量数据输入。
 640-2.webp
640-2.webp
03
2024 年:Milvus 2.4 升级,多向量检索简化复杂业务逻辑
随着易车 AI 助手的功能迭代,用户查询场景变得越来越复杂。比如用户会同时询问 “奥迪 A6 最低配 + 音响品牌 + 油耗”,这类多条件查询。
在之前的架构中,这类请求需要拆分成三个独立检索任务,再通过业务逻辑拼接结果,不仅流程繁琐,还经常出现数据不一致、漏检的问题——比如检索到的最低配车型实际搭载的音响品牌与单独查询的结果不符。
2024 年 6 月,易车将 Milvus 集群升级至 2.4 版本。该版本新增的多向量检索功能,允许在单次查询中融入多个检索条件,通过多向量协同计算语义相似度后直接返回整合结果。无需拆分查询、无需拼接数据,业务逻辑大幅简化。
 3.png
3.png
这一年,易车团队还完成了两项关键建设。
一是高可用容灾体系:基于Milvus的弹性架构设计双集群双写方案,流量高峰时优先同步数据至备份集群,低峰时再同步主集群,配合定时探活机制,成功规避因机房网络抖动、集群异常导致的线上事故。
二是定制化分层索引策略:根据数据量级差异,为千万级参配数据选用IVF_FLAT索引平衡速度与内存(通过自动化平台测试,确定核心参数 nprobe 为 nlist 的 5%-10%,实现检索速度与准确率的最优平衡),为50万-500万条新闻口碑数据选用HNSW图索引兼顾准确率与效率,为小体量FAQ数据选用FLAT索引节省资源,通过参数调优实现检索速度与准确率的最优平衡。
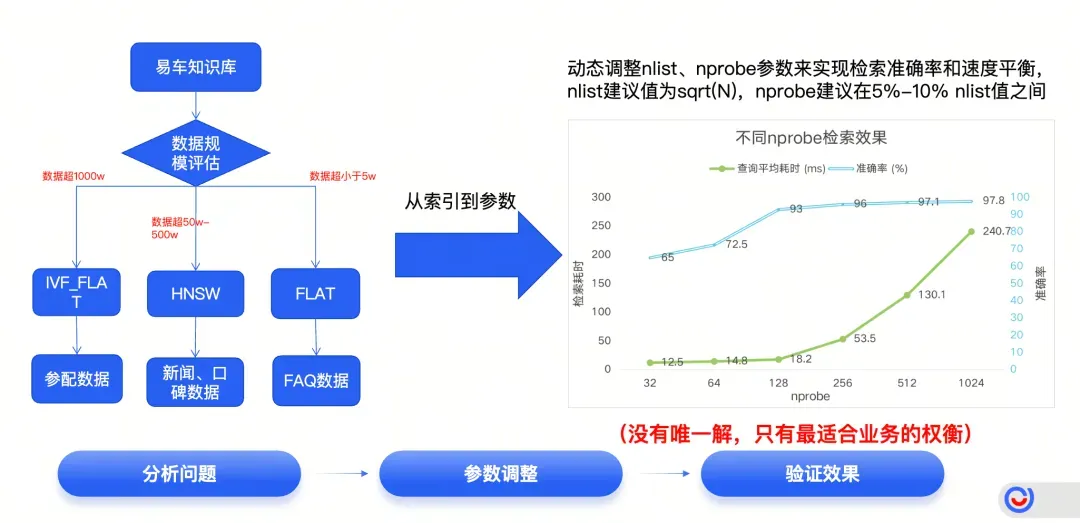 4.webp
4.webp
数据见证了成效:截至2024年底,易车智能助手知识库检索准确率从45%飙升至95%,智能客服知识检索准确率从40%突破至99%(数据来自人工标注的待测数据与AI召回结果的对比计算),用户多条件咨询的满意度显著提高。
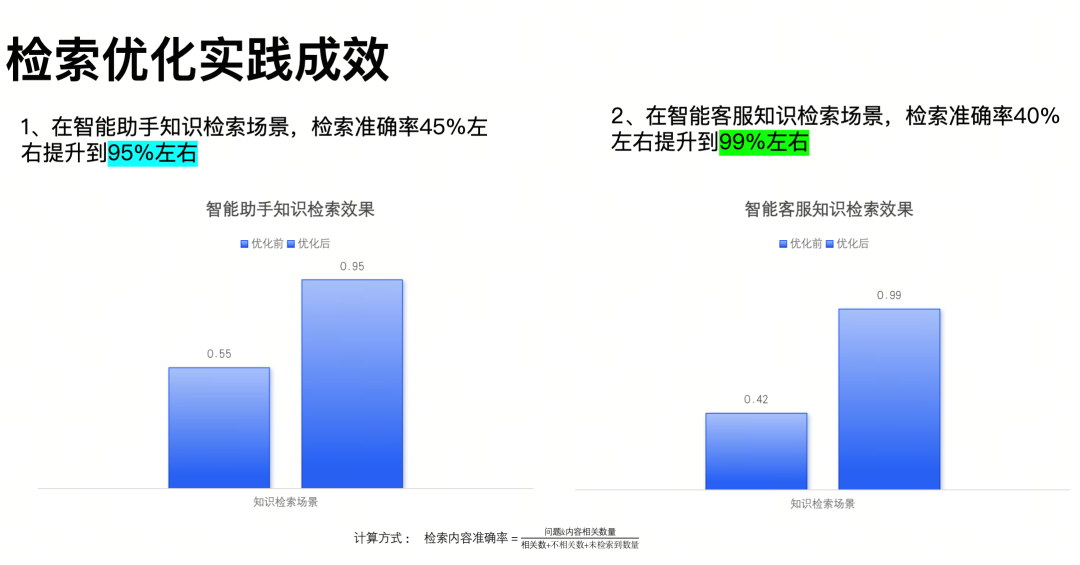 5.png
5.png
04
2025 年:稀疏向量探索,简化架构并提升精准度
在长期实践中,团队发现部分关键词敏感场景(如 “宝马 5 系 2025 款 价格”),仅用稠密向量检索仍存在精准度不足的问题。不得不搭配ES检索形成双层架构。这种架构不仅增加了运维复杂度,还会因两个系统的检索逻辑差异导致结果偏差。
2025 年 4 月,易车开始探索稀疏向量检索,借助 Milvus 对稀疏向量的原生支持,在关键词敏感场景中替代部分 ES 检索功能。
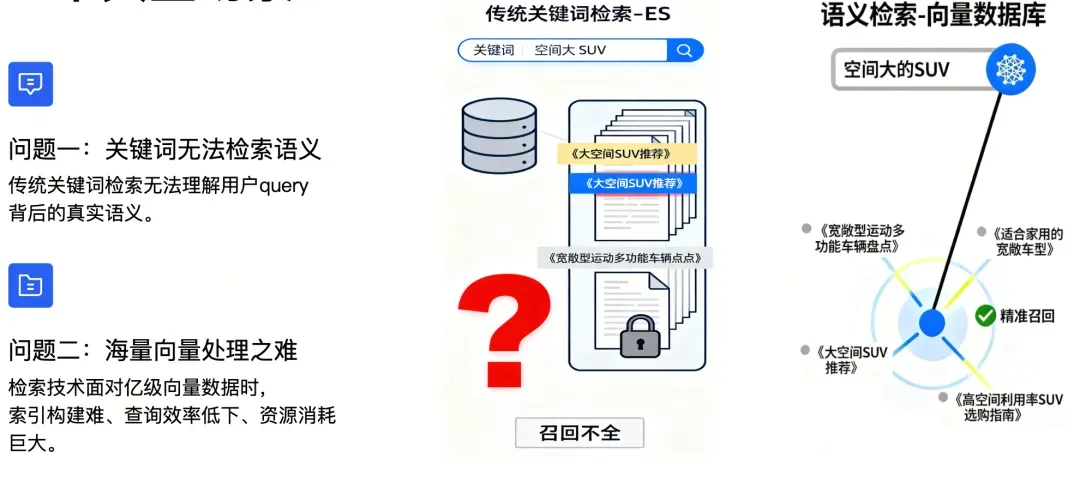 6.webp
6.webp
稀疏向量检索的优势在于对专有名词、精准关键词的捕捉能力更强,与稠密向量的语义理解形成互补。通过 “稀疏向量 + 稠密向量” 的混合检索模式,不仅简化了 “ES+Milvus” 的双层架构,还让关键词敏感场景的检索准确率提升,AI 助手对用户精准需求的响应能力进一步增强。
这个探索过程中,团队也遇到了技术难题:稀疏向量与稠密向量不在同一语义空间,维度差异巨大(稀疏向量数万维,稠密向量数百维),无法直接计算相似度。最终他们采用多路径召回后融合的方案,结合Milvus支持的多种相似度计算方式,通过权重分配筛选最优结果。Milvus官方也透露,后续将强化ranker能力,支持大模型对召回结果二次排序,为这类混合检索提供更优解。
05
做好RAG,不止需要用户向量数据库
在这个过程中,易车发现,要做好RAG架构的落地,只是做好向量数据库的选型与使用只是第一步。
最重要的是积累know how。
比如,易车团队经常面临一个问题,某些爆款新车上市后,用户会批量涌入查询。相应的原 T+1 离线同步无法满足新车上市等实时性需求,导致用户查询新数据时检索失败。
为此,易车选择基于 Flink 实时任务同步(仅做变更数据同步,不做全量数据同步,不会影响业务),通过 Flink CDC 抓取 MySQL、SQL Server、MongoDB 等业务数据源变动,经 Kafka 传输、Flink Job 处理拼接、embedding 后,秒级推送至 Milvus 集群,延迟从 1 天降至秒级。
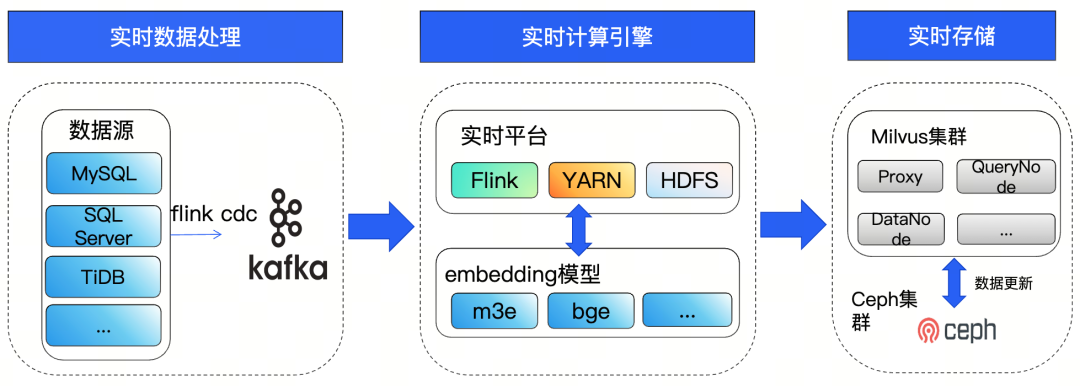 7.png
7.png
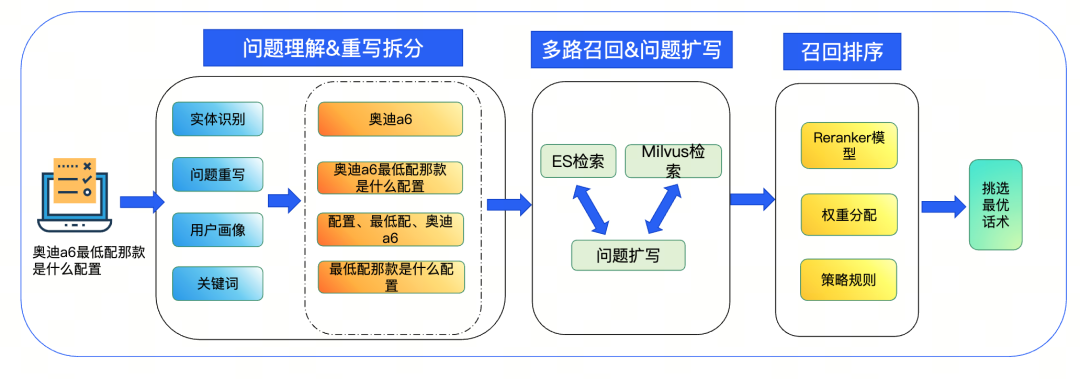
再比如,对于需要的信息,用户的提问往往是残缺或者不标准的,混合检索 + 排序算法优化可以解决90%的问题。但剩下10%需要从预处理、数据扩写等方向入手。
方案包括但不限于,通过实体识别、问题重写、用户画像识别、关键词提取拆分补全用户 query(如 “奥迪 A6 最低配那款是什么配置” 补全为 “奥迪 A6 最低配的配置”)。对待召回数据生成相似问,提升召回率。
 8.png
8.png
这种改动看似微小,但却是智能助手知识库检索准确率从 45% 提升至 95%的重要能力支撑。
06
成果与展望
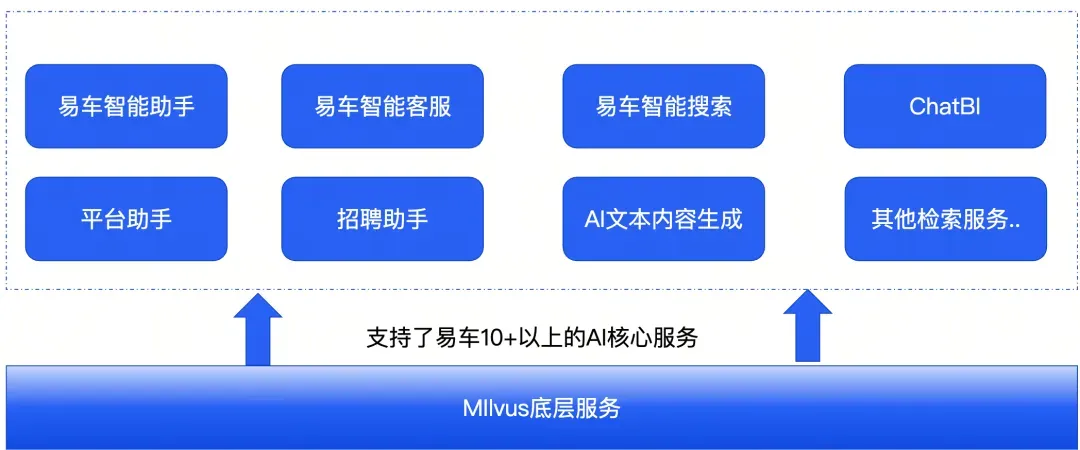
Milvus 之所以能成为贯穿四年的核心支撑,关键在于它的适配性—— 分布式架构适配规模化需求,灵活的索引策略适配多量级数据,持续的版本迭代适配复杂业务场景,开放的生态支持二次开发与定制。这种 可成长、可扩展的特性,正是企业级技术选型的核心诉求。
如今,Milvus 已支撑易车 10 个以上 AI 服务,覆盖 C 端(易车智能助手,让买车机器人更智能)、B 端(易车智能客服,提升用户留资率)及数据层面(赋能 ChaBI)。车企技术客服(24 小时解答车辆故障问题)、企业内部入职培训 / 离职咨询、云上运维(如亚马逊云 IP 占用排查、韧性工程模拟)
 9.webp
9.webp
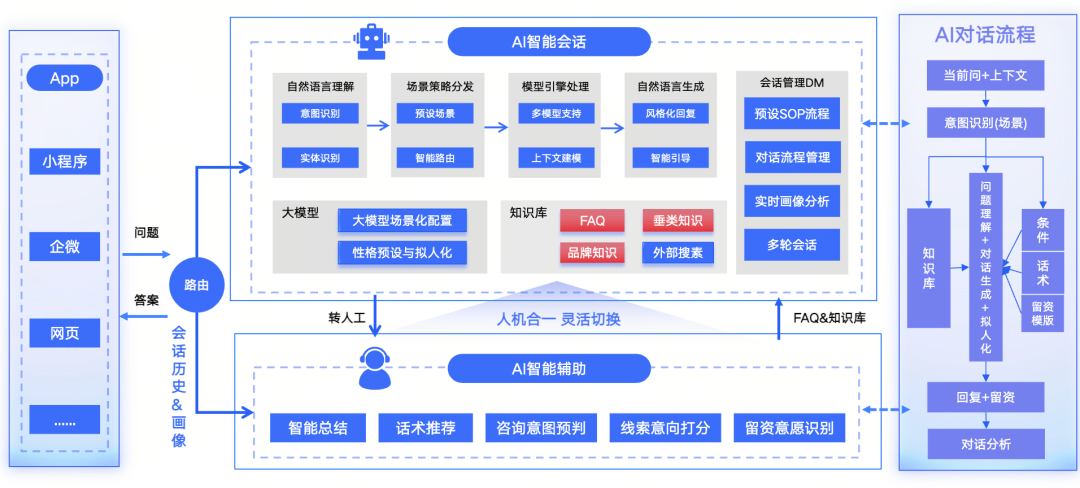
其中,比较值得重点一谈的是易车智能客服:支持 APP、小程序、企微、网页多入口访问,核心模块包括自然语言理解、产品策略分发、模板引擎处理、情感预设、拟人化,底层知识库检索由 Milvus 提供精准召回支撑。
 10.png
10.png
而从整体来看,Milvus覆盖易车各AI项目 90% 以上场景,支持文本、图片、视频精准检索,每日亿级数据写入更新,集群稳定运行。
未来,关于如何用好Milvus,易车计划做这几件事情。
降本增效:统一批数据流,消除外部消息队列依赖;合并协调功能,降低组件通信开销,实现毫秒级响应;智能冷热数据分离,将低访问频率数据存储至低成本介质,降低 50% 存储成本。
检索增强:融合稀疏向量与密集向量加权混合排序,精准捕获关键词语义与生成语义的关联。
持续进化:结合 AI Agent 分析线上 badcase,优化索引构建与数据更新,形成学习闭环,提升召回质量。
 李征
李征

