最新|Milvus_local_RAG,笔记本也能跑的本地知识库&RAG来了
前言
多数前端开发工程师可能都面临这样一个困境:每天需要查阅大量技术文档、项目规范和学习资料。传统的文件夹分类和搜索方式效率低下,经常为了找一个API用法翻遍整个项目文档。
一些大公司,可能会采用企业级知识库方案,通过智能问答来解决这个问题。但问题是:
1、不是所有公司都有这个预算
2、个人部署一套企业级知识库,环境配置复杂、学习门槛高,对新手极不友好
3、使用企业级知识库平替,在线服务又会出现数据隐私泄露风险。
当然,以上问题不止是前端会遇到,所有有复杂文档管理、检索需求的朋友,其实都会遇到。
那怎么解决?这篇“milvus_local_rag”指南正是为你准备的。
这个轻量级RAG方案,用一台普通笔记本就搭建起了个人知识库,查询响应时间,也可以从几分钟缩短到几秒钟。
(备注:本项目是基于Shubham Saboo作者开源的awesome-llm-apps项目二次开发完成的。)
一、核心概念解释
在开始之前,让我们先了解几个关键概念,这样后续的操作会更加清晰:
RAG(检索增强生成):简单来说,就是让AI在回答问题时,先从你的文档库中找到相关信息,再基于这些信息给出答案。就像考试时可以"翻书"一样,让AI的回答更准确、更有依据。
向量数据库:把文档转换成数字形式存储的"智能仓库"。它能理解文档的含义,当你提问时,能快速找到最相关的内容片段。
嵌入模型:负责把文字转换成数字的"翻译官"。它能理解文字的语义,让计算机也能"读懂"文档内容。
二、RAG工作原理:从文档到智能问答的完整流程
了解了基本概念后,让我们看看整个系统是如何工作的:
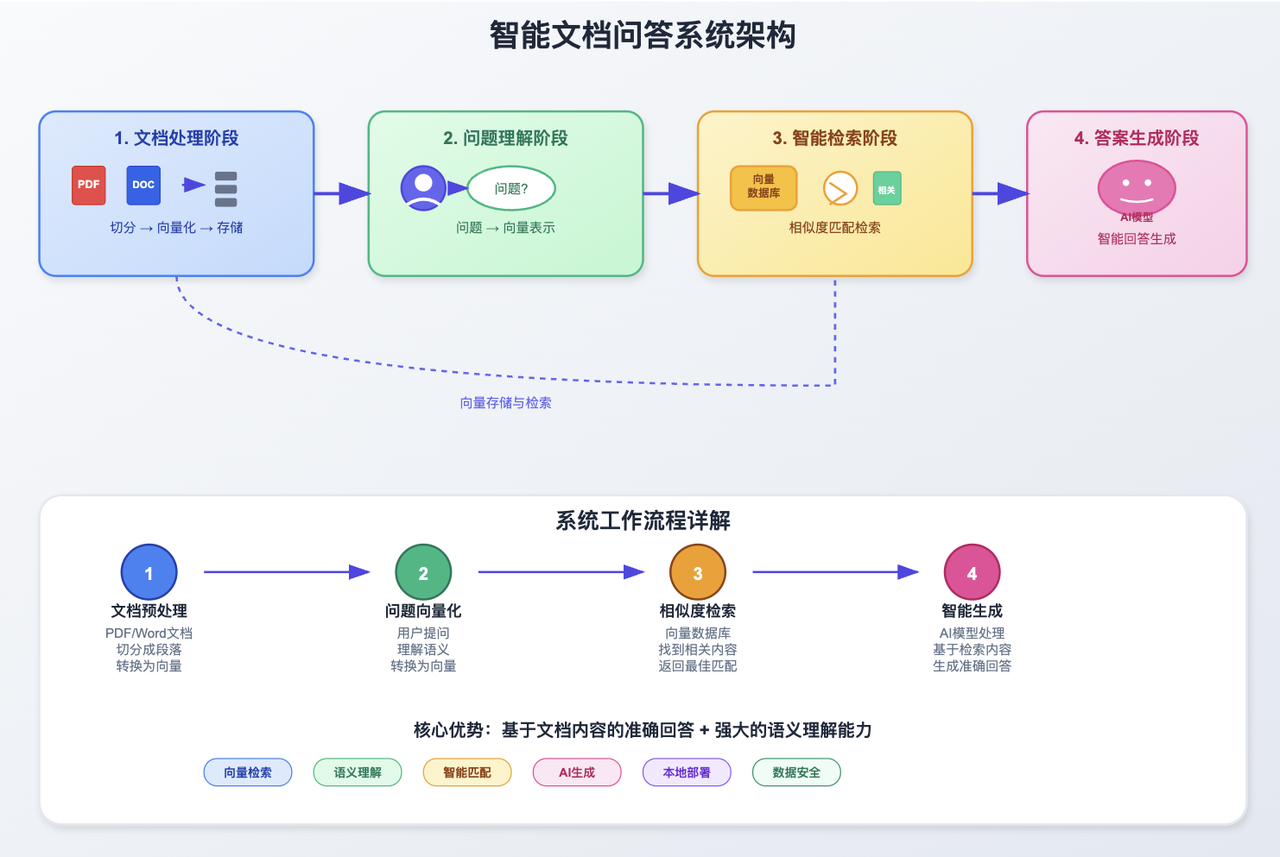
这个流程确保了AI的回答既基于你的文档内容,又具备良好的理解能力。
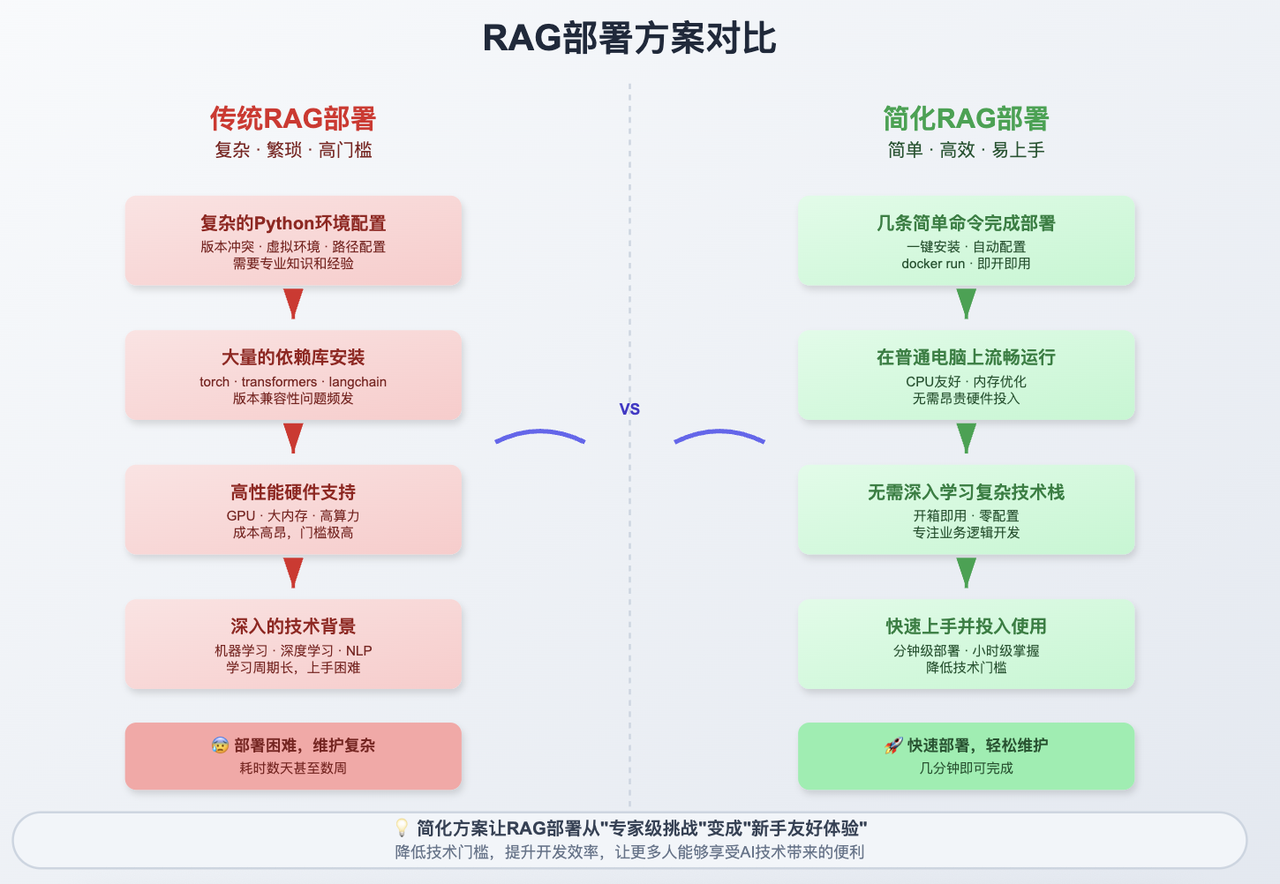
三、为什么选择轻量级方案?
这是一个专为个人用户设计的轻量级RAG项目,核心思路是用最少的依赖实现最完整的功能。整个系统只需要Ollama和Qdrant两个组件,一条命令就能启动完整的本地知识库。
由于项目本身只支持了Qdrant,本文作者对源代码进行了调整后支持了Milvus向量数据库,源码会在文末以链接的方式提供。
核心特点:
真正的本地化:支持Qwen、Gemma等多种本地模型,数据完全不出本地
极简部署:无需复杂环境配置,Docker一键启动向量数据库
智能检索:文档相似度搜索+网络搜索双重保障,确保答案质量
灵活切换:可在纯RAG模式和直接对话模式间自由切换
实际价值:让你用最小的成本获得企业级RAG能力,适合处理个人文档、学习资料或项目知识库,既保护隐私又提供智能问答体验。
四、实践部署
- 环境准备要求
本教程不含Python3、Conda以及Ollama安装展示,请自行按照官方手册进行配置。
相关官网链接:
Python3官网:https://www.python.org/
Conda官网:https://www.anaconda.com/
Milvus官网:https://milvus.io/docs/prerequisite-docker.md
Ollama官网:https://ollama.com
Docker官网:https://www.docker.com/
2.2系统环境配置表
2.2 Milvus向量数据库部署
2.2.1 Milvus简介
Milvus是由Zilliz开发的全球首款开源向量数据库产品,能够处理数百万乃至数十亿级的向量数据,在Github获得3万+star数量。基于开源Milvus,Zilliz还构建了商业化向量数据库产品Zilliz Cloud,这是一款全托管的向量数据库服务,通过采用云原生设计理念,在易用性、成本效益和安全性上实现了全面提升。
2.2.2 部署环境要求
必要条件:
软件要求:docker、docker-compose
CPU:8核
内存:至少16GB
硬盘:至少100GB
2.2.3 下载部署文件
wget https://github.com/milvus-io/milvus/releases/download/v2.5.12/milvus-standalone-docker-compose.yml -O docker-compose.yml
2.2.4 启动Milvus服务
启动服务
docker-compose up -d
docker-compose ps -a

2.3 模型下载与配置
2.3.1 下载大语言模型
#### 下载Qwen3模型
ollama pu
ll qwen3:1.7b
2.3.2 下载嵌入模型
#### 下载embedding模型
ollama pull snowflake-arctic-embed
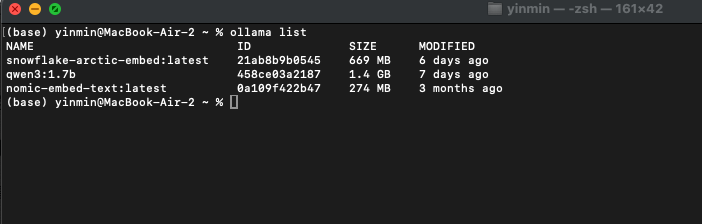
2.3.3 验证模型安装
#### 查看已安装模型列表
ollama list
2.4Python环境配置
2.4.1 创建虚拟环境
#### 创建conda虚拟环境
conda create -n milvus
#### 激活虚拟环境
conda activate milvus
2.4.2 项目代码获取
#### 克隆项目代码
git clone https://github.com/yinmin2020/milvus_local_rag.git
2.4.3 依赖包安装
#### 安装项目依赖
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.5项目配置与部署
2.5.1 参数配置说明
关键配置参数:
COLLECTION_NAME:自定义集合名称(必须配置)
"uri": "tcp://192.168.7.147:19530":Milvus连接地址(必须修改为实际地址)
2.5.2 启动应用服务
#### 启动Streamlit应用
streamlit run release.py
2.6 功能测试与验证
2.6.1 访问应用界面
应用启动后会自动跳转到Web界面,通常地址
http://localhost:8501
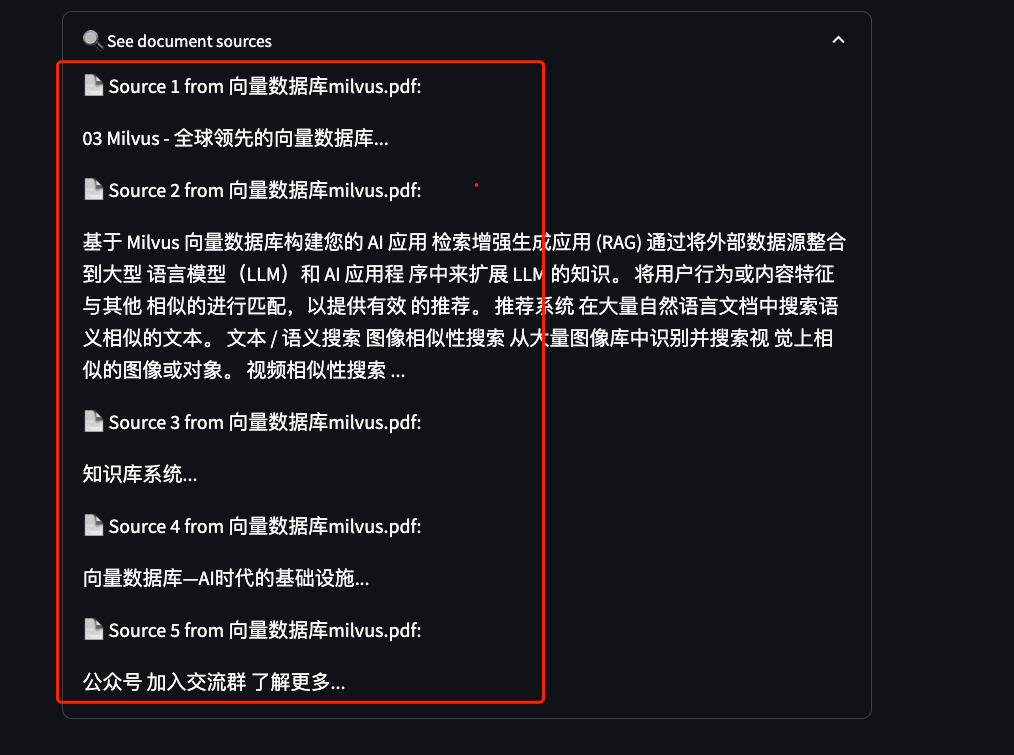
2.6.2 文档上传测试
在Web界面中选择文档上传功能
上传测试PDF文档(建议使用Milvus相关介绍文档)
等待文档处理完成
2.6.3 RAG功能验证
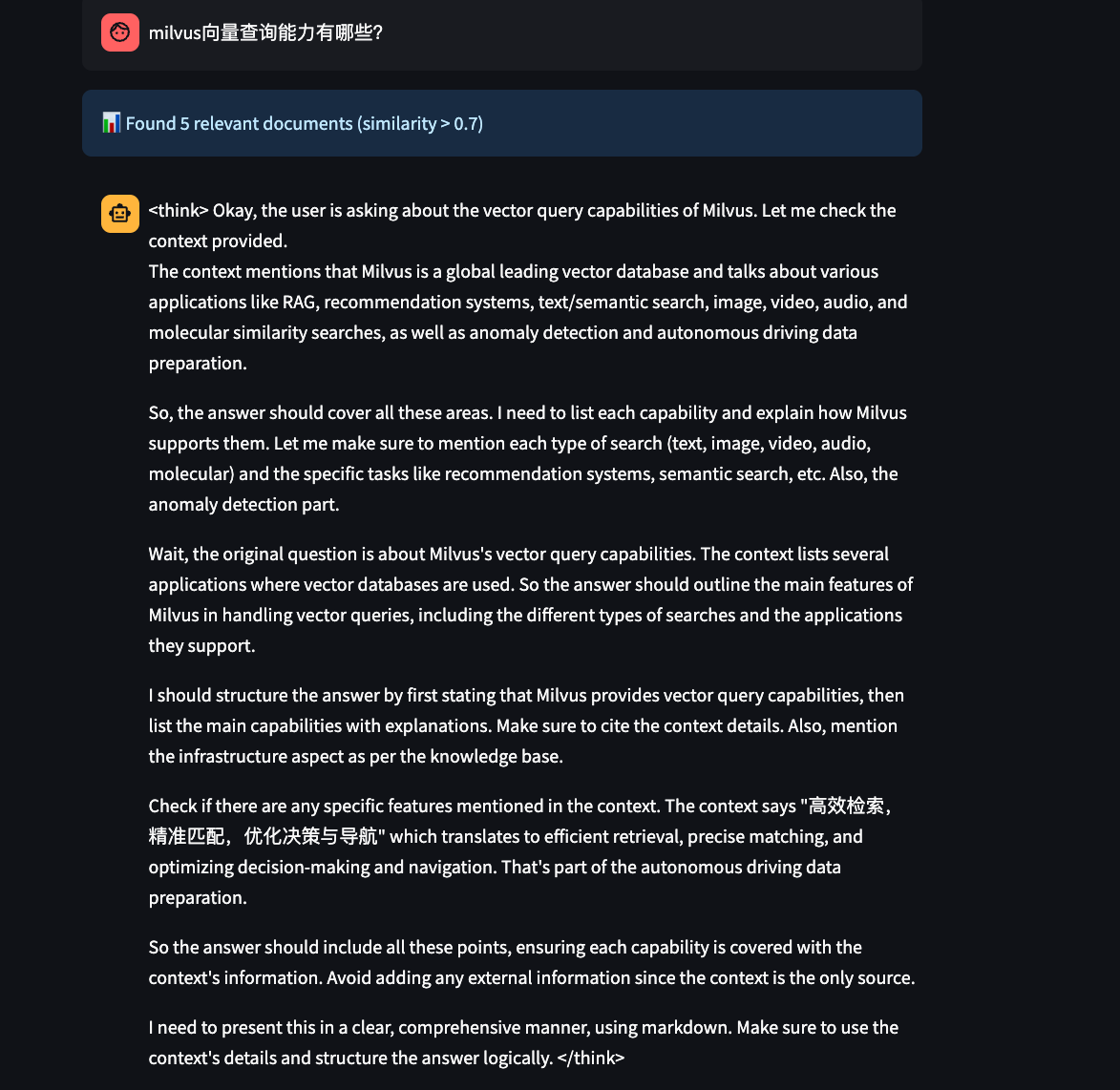
测试查询示例:
milvus向量查询能力有哪些?
通过此查询可以验证:
向量数据库检索功能
RAG(检索增强生成)能力
问答系统的准确性


五、写在最后
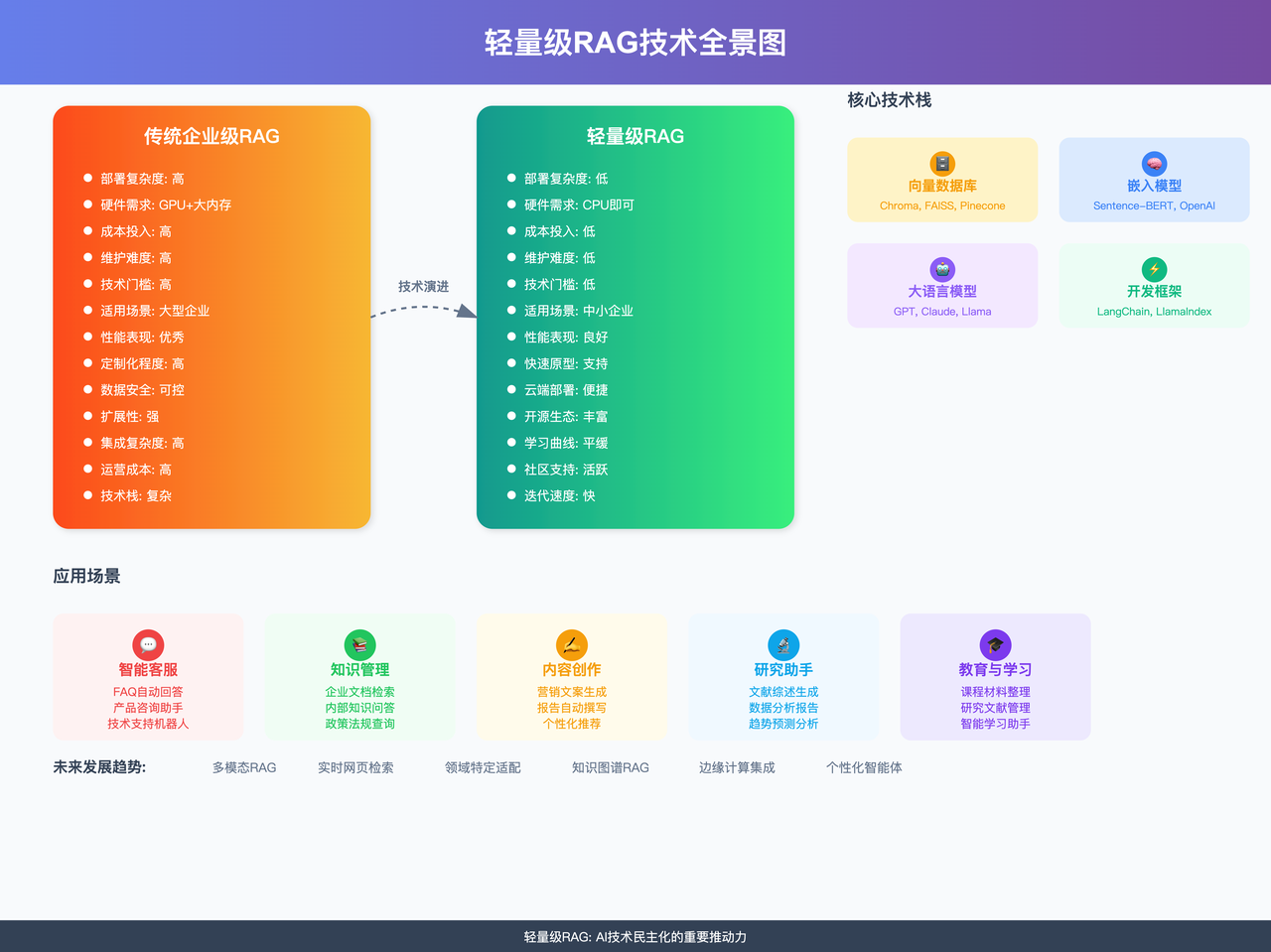
回望文章开头提到的那些令人望而却步的部署障碍:做RAG为什么要让简单的事情变得复杂?为什么要用企业级的重炮去打个人应用的蚊子?
其实,企业级知识库流行的同时,轻量级RAG也逐渐成为了个人侧的主流趋势。轻量级RAG最大的价值在于虽然各种成本低,但能解决的问题很实在。几行代码就能让文档"活"起来,能问能答,而且简单好用,是很多中小企业或者个人用户入门RAG的第一步。
 尹珉
尹珉Zilliz 黄金写手