



Milvus多租户实践:你的技术选型扛得住一夜爆火吗?
引言
选型一时爽,扩容火葬场。
“前期技术架构搭建的时候图简单,就选了一些门槛足够低的入门级数据库,结果等到产品落地、数据量飞涨的时候,用户几天之内从五千涨到十万,服务器崩完,数据库崩,扩容了一礼拜,还是一夜报错8个bug。”
顶级的创意+一流的运维+二流的技术选型=一塌糊涂的产品体验。
这是不是各位AI 时代SaaS企业的真实写照?事实上,AI时代的SaaS,在技术架构上有三条金科玉律:
如果还没有做好AI接入,就不要做产品!
如果产品没有能支撑一夜爆火的弹性,就不要创业!
如果架构设计没有极致的可扩展,就不是真弹性!
以 Airtable 为例,这是一家专注于低代码表格协作的 SaaS 企业,通过可视化的“表 — 关系”模型帮助其用户快速构建业务应用。
由于不同用户的业务模式不同,因此每个用户都需要在底层向量检索引擎中拥有独立的 collection,用于隔离业务数据,自定义数据模型,以及适配不同的 embedding 模型。大多用户的数据体量并不大,而且业务的繁忙时段不同,因此,多租户共用一个集群,一个 collection 一个租户的方案无疑非常适合这个场景。
然而,这个模式随着业务的扩展和客户量的快速增长遇到了问题,尤其是当租户数量攀升至万级以上时,单集群内支持大规模 collection 管理就成了系统性能与运维的最大瓶颈:传统的元数据、RPC 调度和资源分配机制在如此规模下难以承受,查询与加载延迟也会显著提高。
针对这一 SaaS 场景痛点,Milvus 从 v2.5.3 起陆续引入了包括容量上限提升、调度策略优化、内存管理改进等多项核心优化;到 v2.5.8 版本,我们将单集群支持的 collection 数量从数千扩展至十万级,帮助 Airtable 等 SaaS 平台在有限集群资源下按需动态创建和管理租户数据。
接下来,我们将系统性地剖析这些技术优化路径,深入揭示 Milvus 如何突破十万级场景的核心原理与工程实践。
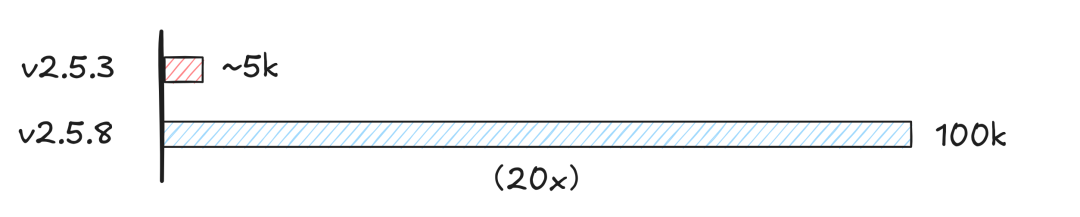 5.7-1.png
5.7-1.png
01 多 collection 场景落地的规模挑战
初期的 Milvus 并没有为多 collection 场景专门进行优化。压力测试显示,在数百 collection 规模下系统表现优异,然而当 collection 规模上升时,系统开始出现以下表现:
操作延迟急剧上升:collection 数量突破 5k 后,关键操作的延迟显著上升,创建 collection 操作从百毫秒上升至几秒,批量插入延迟从几十毫秒上升至几秒,并且操作的延迟还会随着 collection 数量的增加而不断上升,严重影响系统可用性。
后台索引构建任务堆积:在 Milvus 中,数据通过 partition 和 shard 多级分片会形成数据块(segment),Milvus 后台会针对每个 segment 触发多个索引构建任务。在超大规模 collection 集群中,随着数据的持续写入,segment 数量会达到百万级(例如,若系统中有 10k 个 collection,每个 collection 有 100 个 partition,则 segment 数量至少会有 10k * 100 个),因而使得系统触发的索引构建任务会达到数百万个,导致任务积压率持续升高,查询性能衰减,任务调度成为系统瓶颈点之一。
重启恢复慢:百万级 segment 会使得系统的 kv 元数据量达到数百万,系统冷启动或者故障恢复时需 30+ 分钟才能完成元数据加载,加上消息流订阅及数据加载等,系统完整恢复需要耗时几小时以上,严重制约系统的故障恢复速度和可用性。
基于上述瓶颈分析,我们定义了大规模 collection 场景优化的具体要求:
操作延迟稳定;
索引任务高效调度与执行;
系统快速重启恢复;
整体资源使用可控。
02 支持十万 collection 的技术攻坚之路
操作延迟优化
在管理十万级 collection 的场景下,高频操作延迟成为核心挑战。针对不同操作类型,我们通过架构升级与工程实践相结合,系统性优化了关键路径,大幅降低了延迟。主要改进方向包括:
加速元数据访问:重构元数据存储结构,针对高频访问的元数据构建二级索引体系,建立快速查询通道,将原本需要全量扫描的操作转化为精确查询,在 collection 数量超过一定数量级时,元数据查询延迟从原先的秒级降至 微秒级。
提升并发能力:为突破全局锁带来的瓶颈,我们引入更细粒度的锁机制(如按元数据表、任务队列独立加锁),避免“一把锁控全局”的粗粒度模式,显著减少线程冲突,提升并发效率。同时,在部分链路实施无锁化改造,进一步增强元数据处理吞吐。优化后,系统在超大规模场景下依然能高效稳定地支撑海量访问请求。
优化通信流程:在系统优化过程中,我们去除了多余的 RPC 调用链,例如协调节点(MixCoord)间不再通过 RPC,而改用本地函数调用,极大简化了通信路径,降低了网络开销与延迟,显著提升了高并发下的整体性能和稳定性。
在上述优化实施完成后,我们在预设的验证环境中进行了压力测试,重点验证系统在十万级 collection 下的操作延迟稳定性。
测试环境
Milvus MixCoord(8c32g)
Etcd(1c1g) × 3
Milvus version: v2.5.3 vs v2.5.8
测试方案
持续创建 collection
每个 collection 插入 1000 条向量数据
向量维度:128
客户端并发数:10
测试结果
测试显示,在 10 万 collection 级别,CreateCollection 操作的延迟从 5.62s 下降到 501ms ,性能提升 11 倍。Insert 操作从 7.2s 下降到 52.6ms。性能提升 137 倍。实测结果表明,相比于优化前的 v2.5.3,Milvus v2.5.8 在面向十万级 collection 的复杂场景下,不仅成功支撑了集群级别的横向扩展,还显著优化了关键路径的操作性能。所有操作延迟均保持在可用的级别,具备支撑超大规模多租户的能力。
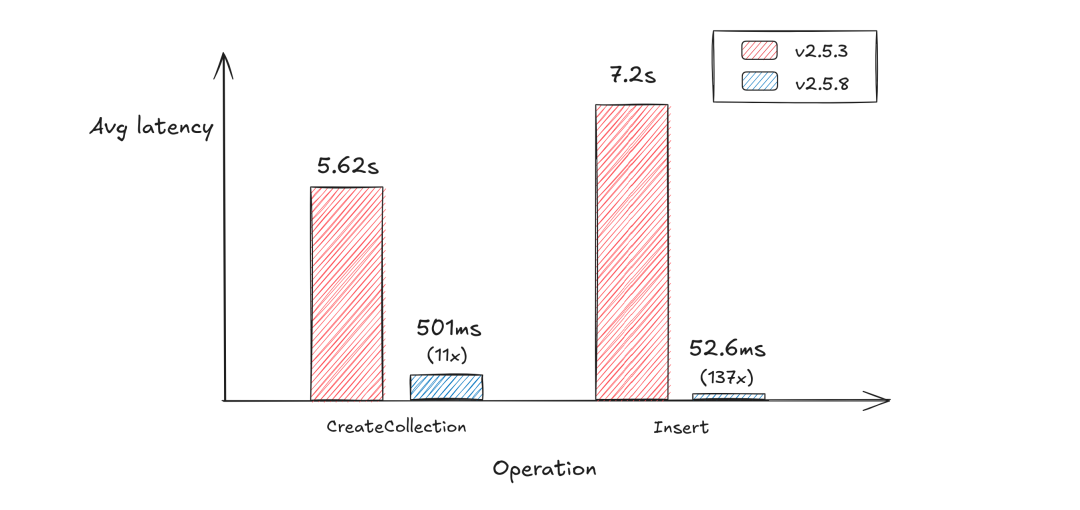 5.7-2.png
5.7-2.png
索引任务调度优化
在 Milvus 中,索引任务会由协调节点进行调度,由工作节点(DataNode)负责执行。在之前的版本中,协调节点为索引任务分配工作节点时采用“一任务一节点”的策略,导致两类典型问题:
资源碎片化:小任务占用整机资源,造成 CPU 和内存的闲置浪费;
资源争抢:大任务因资源不足频繁等待,形成调度瓶颈。
新版本中,我们引入了索引任务动态评估模型,基于数据规模等特征参数,设计了资源量化评估模型,以 2c8g 为 DataNode 的基准计算单元,通过实时分析任务的权重系数为任务分配资源。该模型会持续监测任务执行状态,当检测到大量索引构建任务时,会开启并发调度,同时执行多个任务,以达到资源最大化利用的目的。
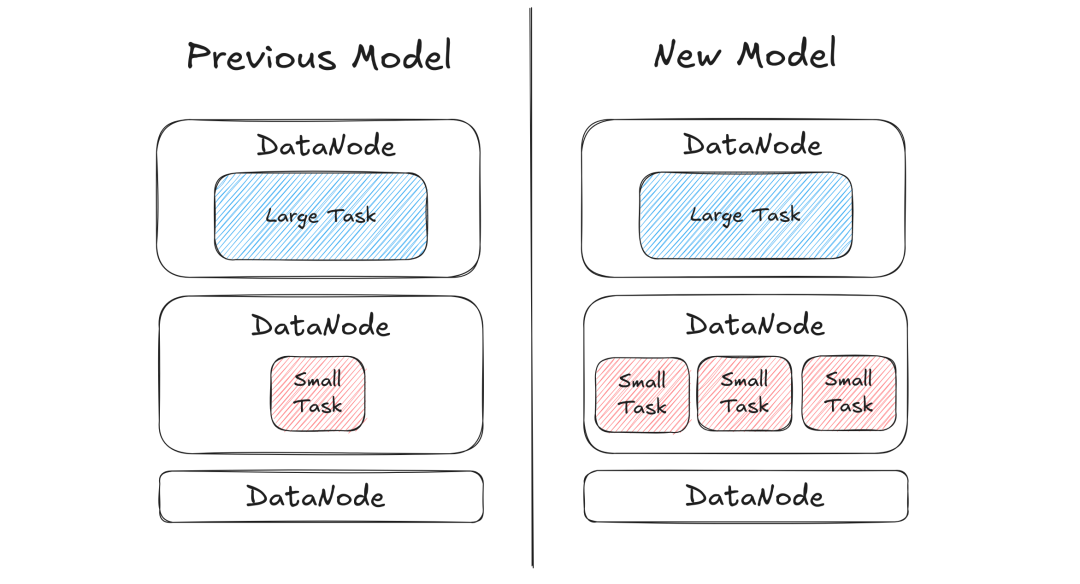 5.7-3.png
5.7-3.png
调度侧,引入了双缓冲队列结构,将任务执行与轮询解耦,执行线程处理当前排队队列时,调度器可在执行队列中编排后续任务,消除资源空窗期。对于只需要线程安全的链路,元数据管理采用无锁结构替代传统锁机制,规避了线程竞争导致的系统颠簸。两项优化共同降低资源争抢,使单集群十万级 collection 的索引任务调度延迟稳定在毫秒级。
在标准测试环境中,我们部署了 4 个 DataNode(4c16g)用于索引构建,对千行 segment 的小型索引任务进行压测。优化后系统展现出优异的性能:通过动态资源调度算法与双缓冲队列的协同作用,任务吞吐量从优化前的 10k/小时跃升至 300k/小时,实现 30 倍提升。
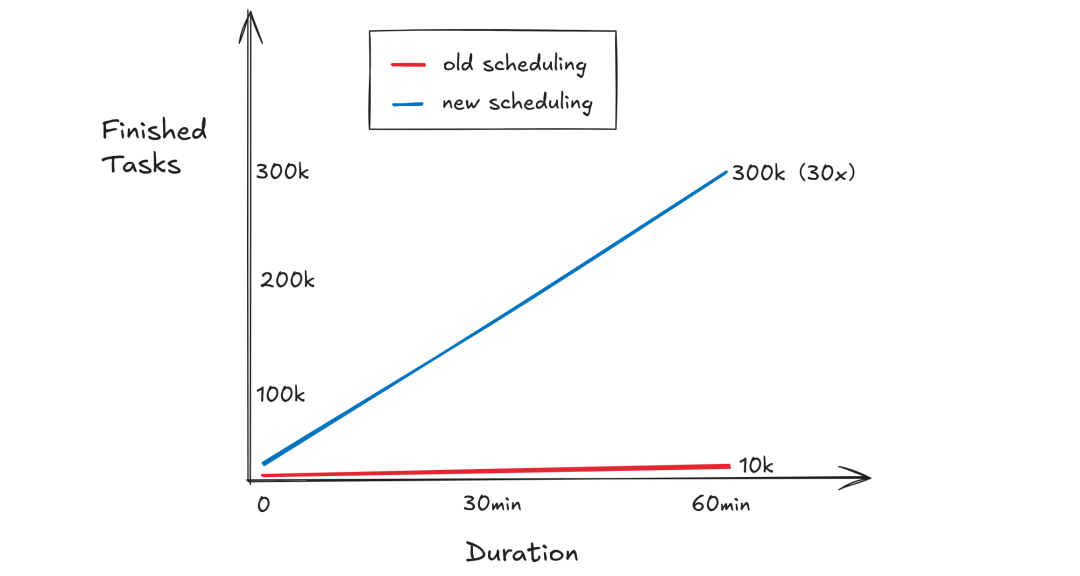 5.7-4.png
5.7-4.png
Rocovery 速度提升
在应对超大规模 collection 集群重启恢复挑战时,我们针对元数据恢复与消息流订阅两大核心链路进行优化,极大地优化了海量 collection 场景下的启动慢的问题。
- 元数据恢复性能突破:当单个集群需要同时管理十万级 collection 时,系统内部用于记录 collection 结构、分区信息、segment 等的元数据会迅速膨胀,最终在存储层形成数百万级别的 kv 对象。每个 kv 需经历反序列化、版本校验、状态重建等复杂流程。早期版本恢复元数据时采用串行加载机制,串行执行模式下,系统启动耗时与数据量呈线性增长,实测 300 万 kv 加载耗时长达 30 分钟,严重制约集群可用性。新版本引入了并行化加载逻辑,将 kv 数据按 collection、partition 等级别进行拆分,基于 Go 协程池调度框架,将每个 collection 单元作为独立任务分配至空闲协程,实现并发加载。优化后,300 万 kv 元数据加载耗时从 30 分钟降至 1 分钟,性能提升达 30 倍。
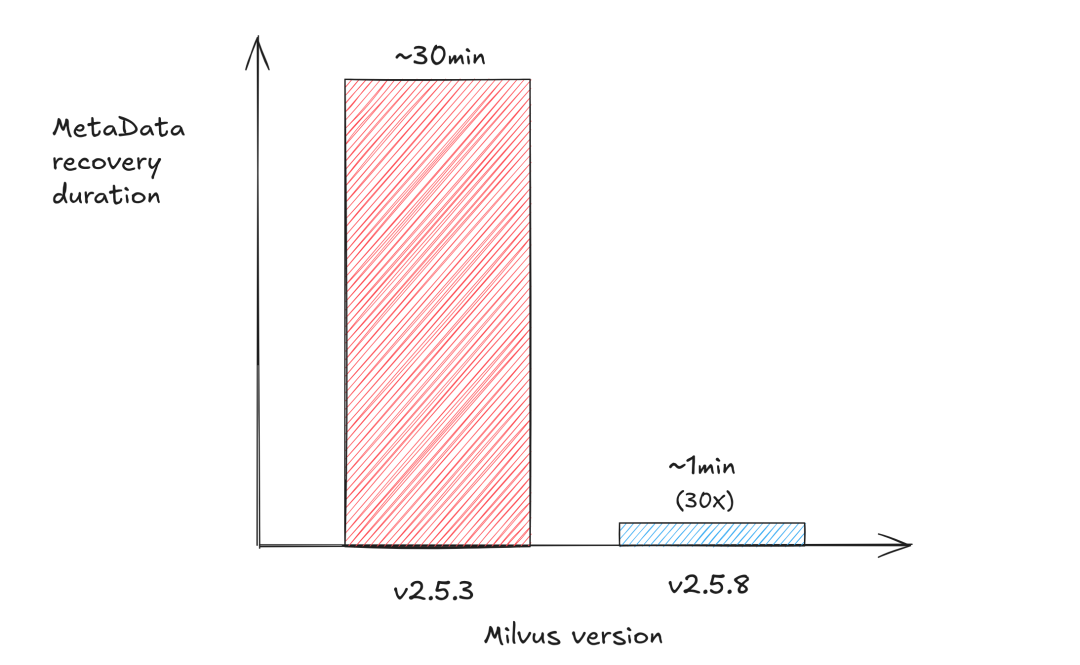 5.7-5.png
5.7-5.png
消息流订阅模式优化:Milvus 启动恢复时,需要为每个 collection 重建消息流订阅,旧版本架构会为每个 collection 独立创建消息流订阅,当集群管理十万级 collection 时,订阅过程将产生显著影响:
效率瓶颈:以单机 1k collection/十分钟的订阅速度计算,十万 collection 需要 1000 分钟(约 17 小时)才能订阅完成;
读放大:多个订阅消费同一物理 topic,读放大严重,导致消息被重复拉取数千次,引发消息存储系统 IO 吞吐量暴涨;
内存消耗:假设单个订阅需要 32MB 内存,仅千个 collection 的订阅就占用了 32GB 内存。
新版本我们引入订阅协调器 “Dispatcher”,根据 collection 数量划分为多个订阅组(如 10 万集合划分为 200 组),每组仅需进行一次消息流系统的订阅,实现“批式”订阅。每次订阅后,Dispatcher 会对消息进行分发,根据 collection ID 高效路由至各处理单元。
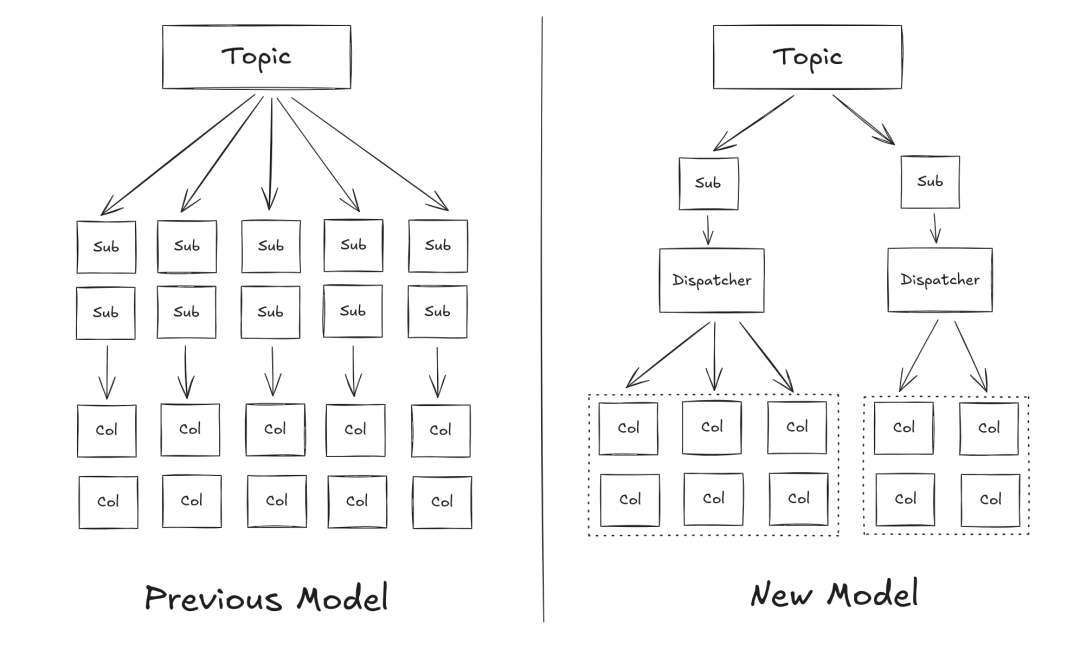 5.7-6.png
5.7-6.png
这种"批式订阅+智能分发"的模式使得订阅耗时从原先的 1000 分钟缩短至 1 分钟,提速千倍,同时通过单次读取、多次分发的设计,避免了读放大和内存问题,即使面对 10 万级集合同时启动的极端场景,系统也能像处理数百个集合一样快速响应。
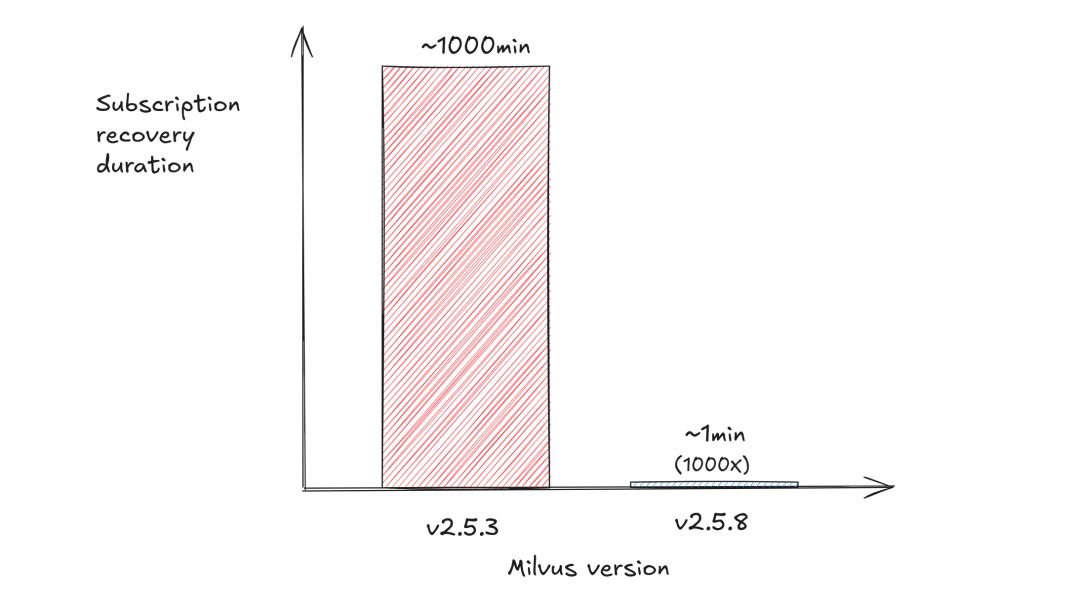 5.7-7.png
5.7-7.png
实测表明,两项核心优化使得大规模 collection 集群启动时间从小时级缩减至分钟级,这一突破提高了系统容灾恢复能力,确保高敏感场景的业务连续性,同时为突发流量下的秒级集群扩容提供底层支撑,大幅降低业务中断风险与运维成本。
内存优化
在高并发、多租户场景中,用户行为存在显著的不确定性,其中最常见的是误操作。例如,一些用户经常将 Upsert 替代 Insert 使用,这类操作往往会导致系统收到大量不存在主键的 Delete 请求。在 Milvus 中,处理 Delete 操作时通常会先借助 BloomFilter 判断主键是否存在,从而避免浪费资源在为不存在的数据进行 Delete 操作。
但问题也随之而来:在百万级 segment 场景下,BloomFilter 带来的内存消耗是巨大的。我们简单计算一下,假设每个 BloomFilter 的元素个数为十万,假阳性率为 0.001,其内存占用约为 175KB。当系统中 segment 数量达到一百万时,光是 BloomFilter 的总内存就高达 175GB(175 KB × 1million),这对于集群来说是极大的负担。
为此,在 Milvus 2.5.8 中我们做出调整:DataNode 不再将 BloomFilter 加载至内存,所有 Delete 记录直接持久化到底层对象存储。这意味着即便 Delete 的主键在当前数据中不存在,也不再进行过滤,而是交由后续阶段统一处理。这一策略的优势在于:
显著降低内存开销:释放大量因 BloomFilter 带来的驻留内存;
最终一致性由 Compaction 机制保证:Milvus 的 Compaction 机制会在后台合并数据时,自动清理这些无效 Delete,从而最终消除冗余记录。
一个简化的 Delete 处理流程如下:
用户发起 Delete 请求,主键可能存在,也可能尚未写入;
DataNode 直接将 Delete 记录写入 binlog,不再判断主键是否存在;
若 Compaction 时发现主键存在,则主键被成功删除;
若 Compaction 时发现主键不存在,则丢弃 Delete 记录。
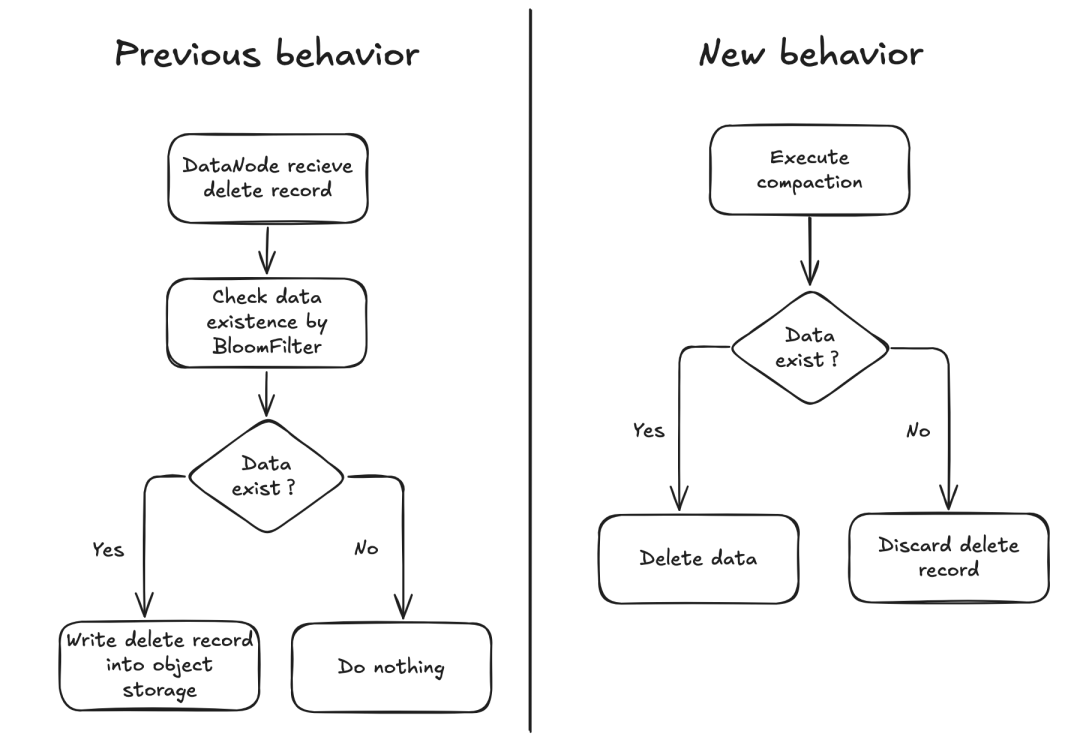 5.7-8.png
5.7-8.png
这项调整不仅大幅降低了 Datanode 的内存占用,还简化了数据路径,提高了系统在复杂场景下的稳定性,是十万级 collection 优化路径中一项典型的“以简制繁”的实践。
结尾
回到 Airtable 的使用场景,在采用 Milvus v2.5.8 后,其团队无需再为持续增长的租户部署更多 Milvus 集群。通过维护一个 Milvus 集群,为每个租户创建单独的 collection 即可实现租户级隔离。对用户而言,每个“智能表格”背后都对应一个独立的向量 collection,支持自定义的搜索、分类与推荐模型,在不增加运维成本的前提下,用户的使用体验依然得到了保证。
Milvus v2.5.8 支持单集群管理十万级 collection,帮助企业在单一集群上高效运行大规模多租户向量检索服务。无论是构建百万级智能文档、客服机器人,还是企业级 AI 数据协作平台,一个能够承载海量 collection 的高扩展性向量数据库,是支持多租户应用的基础设施核心。未来,随着 AI Saas 应用的落地和持续演进,Milvus 作为超大规模向量数据库的弹性扩展能力,将成为驱动 AI 基础设施升级的核心引擎。
 戴一豪
戴一豪


