



局部敏感哈希(L.S.H.):全面指南

在大数据和机器学习时代,高效地在大型、高维数据集中找到最近邻或相似项是许多应用中的基本挑战。以音乐流媒体服务Spotify为例。为了提供个性化的歌曲推荐,它需要从数百万首歌曲的庞大库中快速识别与用户偏好最相似的曲目,每首歌曲都由数百个属性如音频特征、歌词、流派等表示。这是一个高维近似最近邻搜索问题。
传统的技术如线性扫描或空间划分树方法随着维度和数据点数量的增加而变得计算上不可行。这就是局部敏感哈希(LSH)和有时基于哈希的索引发挥作用的地方。LSH是一种近似技术,通过智能地将相似数据点映射到相同桶或位置,大大提高了高维相似性搜索的效率。这使您只需探索一小部分候选者,而无需与整个数据集进行全面比较。
相似性搜索的本质和挑战
相似性或向量相似性搜索是信息检索和数据驱动应用中的技术。目标是通过比较它们在高维空间中的空间距离,识别与给定查询向量相似的项目或数据点。
这种技术在许多用例中发挥着至关重要的作用。例如,在电子商务中,相似性搜索驱动产品推荐引擎,为用户提供符合其偏好的选择,从而丰富了购物体验。在多媒体服务中,它使检索与特定模式或主题相符的图像、视频或音乐成为可能,增强了内容的可发现性和用户参与度。然而,相似性搜索在处理大型和高维数据集时面临重大的计算挑战。传统的蛮力方法将每个数据点与每个其他点进行比较,由于它们的二次时间复杂度,在大数据环境中不切实际且耗时。因此,我们需要一种有效的方法,快速确定相似项,而无需进行全面的成对比较,简化在广泛数据集中的搜索过程。
什么是局部敏感哈希(LSH)?
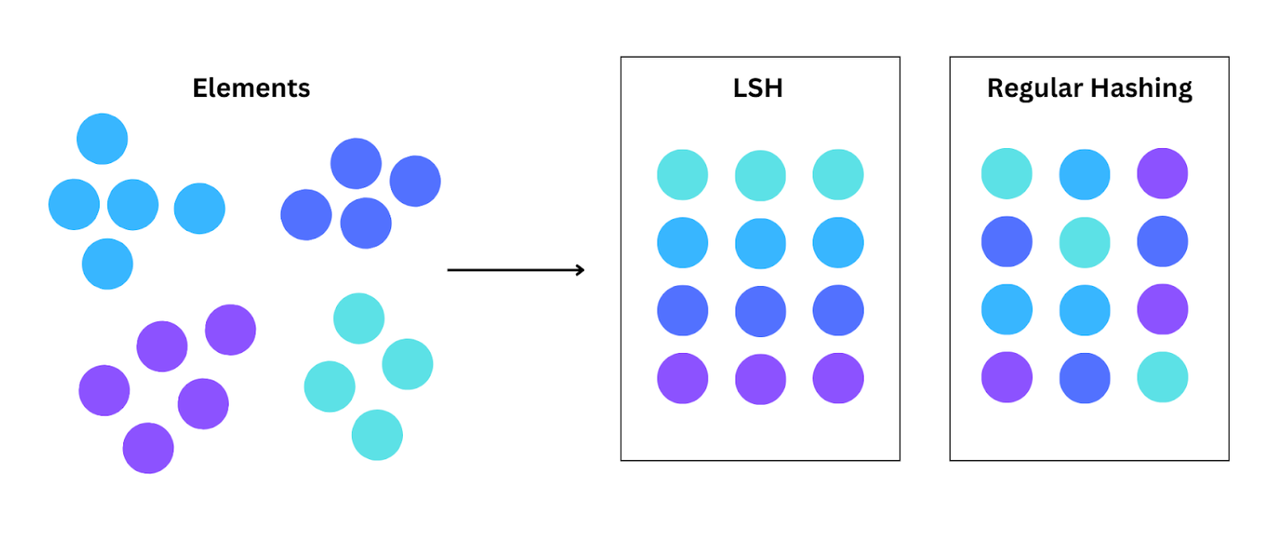
局部敏感哈希(LSH),由Indyk-Motwani在1998年引入,是一种用于近似最近邻(ANN)搜索的技术,它支持并加速了相似性搜索的效率。与传统哈希不同,后者主要关注映射每个数据点,LSH将相似数据点组合在一起。这是通过其“局部敏感性”实现的,它确保原始数据空间中接近的点最终会在同一位置,也称为“桶”。
 30-1.png
30-1.png
LSH与常规哈希的比较
由于LSH将相似数据集组合在一起,相似性搜索可以迅速缩小范围。它通过专注于高维空间中更接近的潜在相关数据点,加快了搜索速度。这种方法使其适用于推荐系统中的最近邻搜索、重复检测等应用。
LSH如何工作?
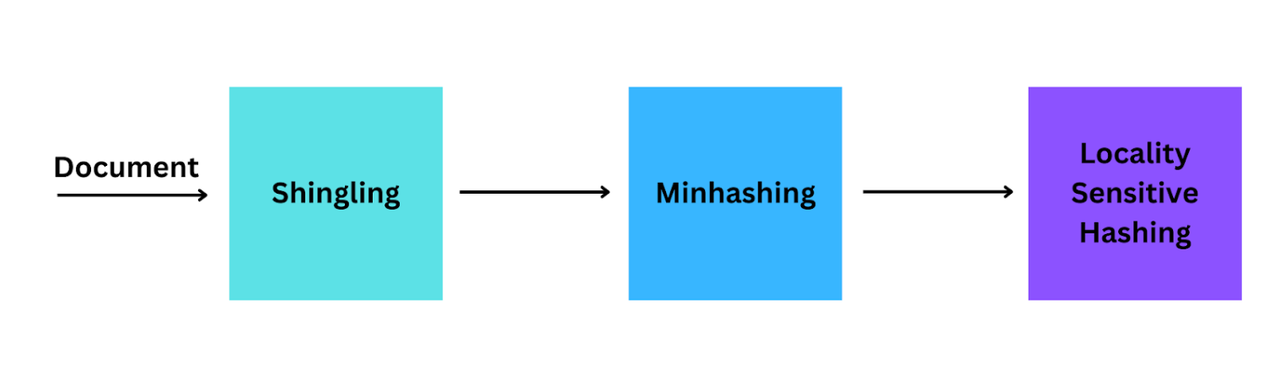
局部敏感哈希的操作分为三个主要步骤:Shingling、Minhashing和局部敏感哈希。
 30-2.png
30-2.png
LSH算法的关键步骤
Shingling
这一步侧重于将文档转换为长度为k的字符集(也称为k-shingles或k-grams)。这种转换允许您根据集合相似性度量(如Jaccard相似性)来表示要比较的文档。
Minhashing
这种技术通过分配Minhash签名并比较它们来研究两个数据集之间的相似性。使用签名来比较这些集合,因为它们以更短的形式捕捉了文档内容的本质。这是使用Jaccard指数的步骤。两个集合的Jaccard指数是公共元素的数量除以所有元素的长度。
LSH技术
这一步包括将相似项聚集在一起。随机投影是一种用于降低一组点的维度的技术。LSH技术使用多个随机投影函数将文档签名映射到低维空间。这结束了这个过程,因为随机投影被设计成相似的签名可能会被映射到同一个桶中。
实现LSH
要实现LSH,您可以使用我们在以下代码片段中包含的几个步骤。
首先包括以下库。
import numpy as np
完成此操作后,您可以定义哈希函数。
def hash_function(datapoint, random_vector):
"""
Hashes a datapoint using a random projection vector.
Args:
datapoint: A NumPy array representing the datapoint.
random_vector: A NumPy array representing the random projection vector.
Returns:
A single-bit hash value (0 or 1).
"""
projection = np.dot(datapoint, random_vector)
return 1 if projection >= 0 else 0
这个函数接受一个数据点和一个随机投影向量作为输入。它计算它们之间的点积,如果投影是非负的,它返回1。否则,它返回0。这个过程根据数据点和随机向量之间的关系创建了一个单比特哈希值。
生成随机投影矩阵。
 30-3.png
30-3.png
更具体地说,让我们讨论这个函数的作用。num_projections是一个整数,详细说明了您想要创建多少个随机投影向量,而data_dim是另一个整数,显示了您的数据点的维度。
总的来说,这个函数生成一个矩阵,其中每一行都是一个随机投影向量,您可以稍后使用它将数据点投影到较低的维度空间,为下一个函数,局部敏感哈希,做准备。
开始操作局部敏感哈希。
 30-4.png
30-4.png
lsh_hash函数使用多个随机投影哈希数据点,这是LSH过程中的核心步骤。第一行包括NumPy数组datapoint和random_matrix,分别代表要哈希的数据点和用于哈希的随机投影矩阵。
继续进行过程步骤,初始化步骤由hash_values执行,它创建一个空列表来存储生成的哈希值。
这之后是迭代过程,通过随机投影向量完成。random_matrix循环遍历每一行,然后random_vector调用hash_function,将datapoint和random_vector作为参数。
然后您将在hash_values列表中获得返回值,包含每个随机投影向量的哈希值。
示例数据点
 30-5.png
30-5.png
这段代码片段生成了一个示例数据点。它定义了随机投影的数量和数据维度,生成了一个随机投影矩阵,哈希了数据点,并以1和0的形式打印了哈希值。
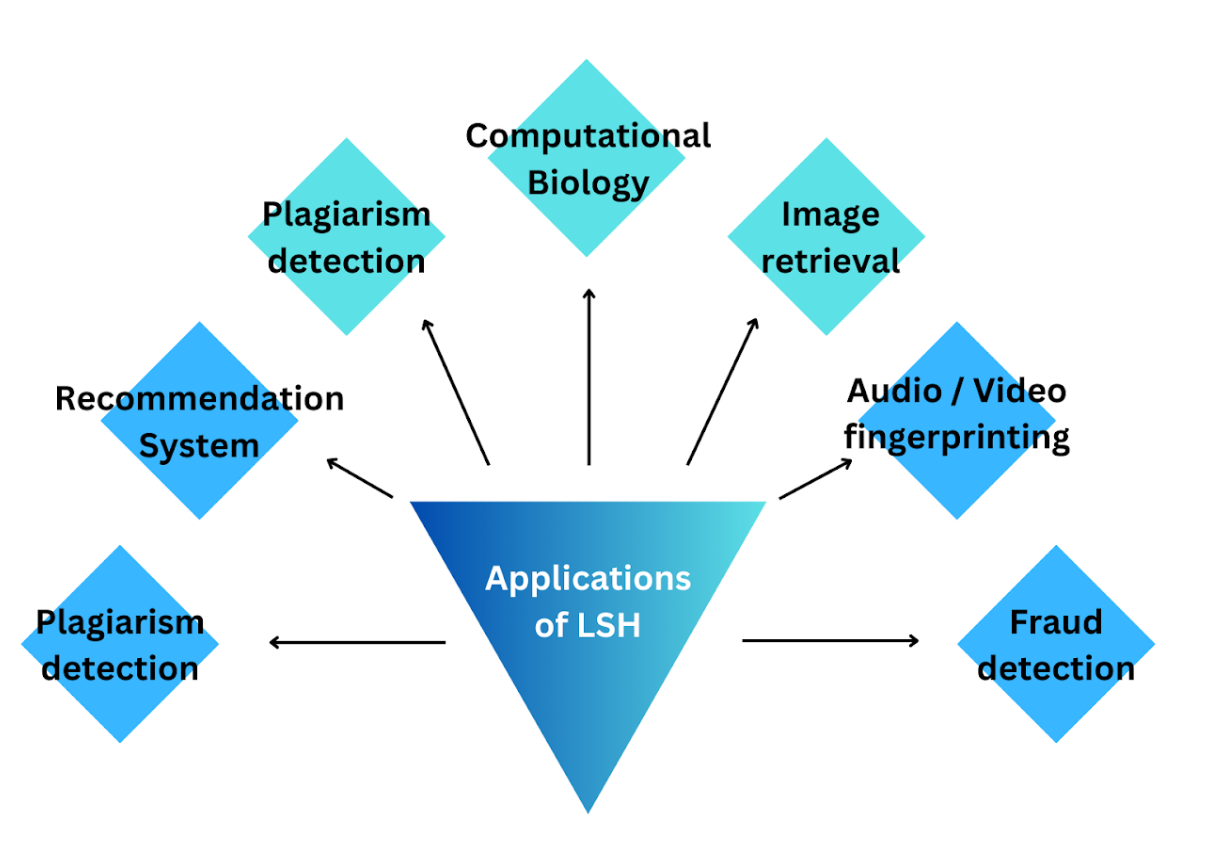
LSH的应用和用例
LSH旨在有效且高效地进行相似性搜索,这使它们在各个领域具有广泛的应用。
 30-6.png
30-6.png
LSH的应用
它最常用的用例之一是在计算生物学中,特别是在基因和蛋白质序列分析中。这是因为LSH可以帮助在基因组数据库中识别相似的基因表达,尤其是因为基因表达数据通常具有高维度。
LSH的另一个广泛使用的应用是图像检索。LSH将高维图像数据映射到较低的表示,同时保持数据之间的相似性。这有助于快速检索与查询图像相似的图像。这适用于库存照片服务,用户请求某些视觉效果,医学图像分析,找到类似案例可能有助于诊断等。它还改进了图像检索应用中的哈希技术和压缩性能。LSH也用于抄袭检测软件。它有助于识别文档之间的相似性,通常带有百分比并突出显示相似区域。LSH还有其他应用,如视频检索、社交网络分析、推荐系统和数据挖掘,所有这些都归功于它发现数据集之间相似性的能力。
总结
局部敏感哈希(LSH)是处理大型、高维数据集复杂性的关键技术,简化了相似性搜索和数据检索的过程。它将相似数据点有效地映射到降维空间中的相同“桶”中的能力,使其成为各个领域中不可或缺的工具。从为电子商务中的推荐系统提供动力到促进计算生物学中的高级研究,LSH在提高搜索效率和准确性方面的作用是不可否认的。

Shanika W.
Freelance Technical Writer


技术干货
Zilliz Cloud 明星级功能详解|解锁多组织与角色管理功能,让你的权限管理更简单!
Zilliz Cloud 云服务是一套高效、高度可扩展的向量检索解决方案。近期,我们发布了 Zilliz Cloud 新版本,在 Zilliz Cloud 向量数据库中增添了许多新功能。其中,用户呼声最高的新功能便是组织与角色的功能,它可以极大简化团队及权限管理流程。
2023-6-28
技术干货
可处理十亿级向量数据!Zilliz Cloud GA 版本正式发布
本次 Zilliz Cloud 大版本更新提升了 Zilliz Cloud 向量数据库的可用性、安全性和性能,并推出了一系列新功能。这次升级后,Zilliz Cloud 能够更好地为用户提供面向各种应用场景的向量数据库服务,不断提升用户体验。
2023-4-7
技术干货
如何设计一个面向开发者全生命周期成本的全托管向量检索服务产品?
作为产品的设计者和开发者,必须始终以用户为中心,积极倾听他们的需求,并集中精力降低软件开发的全链路成本,而非过度追求极致性能或过分炫技。在这种背景下,降低开发者的综合使用成本已成为 Zilliz Cloud 和开发团队过去的主要使命。
2023-7-5