



Langchain 吐槽OpenAI根本不懂 AI agent和workflow?知识点全解析
前言
最近,OpenAI 最近发布了一篇关于构建 Agent 的指南。
结果发出没多久,就被LangChain专门发布长文吐槽,8行内容出了8处错误。
包括但不局限于:
1、LangGraph 并不是完全声明式的框架
2、“当工作流变得更加动态和复杂时,这种方法很快就会变得繁琐和困难”——这段话的本质问题不是“声明式 vs 非声明式”,而是“workflow vs agent”,用户可以在Agents SDK 中以声明式图的方式表达代理逻辑。
3、workflow根本不需要那么多的动态性或复杂性,也不是所有场景都要用workflow或者agent。
4、Agents SDK 不是命令式框架,它是抽象层。而它的这些抽象,本质上也是一种领域特定语言。
5、 Agents SDK 里能做的事,在框架里都能做,不存在框架不灵活。
6、Agents SDK 不存在“更代码优先”。
7、Agents SDK并不是使用熟悉的编程结构就搞定的,你得学习一整套新抽象。
8、更动态、适应性更强的代理编排,这还是和声明式 vs 非声明式无关,依旧是“workflow vs agent”的问题。
 4.22-1.png
4.22-1.png
(图:OpenAI的教程原文)
而双方吐槽也引起了众多海外开发者的吃瓜围观。在这里,我们对LangChain的檄文做了摘编翻译,帮助大家理解双方争论的重点到底是什么。
此外,去掉其中的双方口水战环节,文章中给出的反驳,同样干货满满,堪称是agentic system选型指南,可以快速帮助开发者们梳理清楚agentic system开发中的常见问题,以及相关业务构建逻辑,非常值得一读。
接下来,本文会从以下角度展开内容:
背景信息: 什么是agent?构建agent难点是什么?LangGraph是什么?
代理框架的分类: “agent” vs “workflow”、声明式 vs 非声明式、agent抽象、多代理
常见问题: 框架的价值是什么?随着模型变得越来越好,agent会取代workflow吗?OpenAI 的看法有什么错误
01
背景解读:LangChain声讨OpenAI前给出的共识
本章节主要解读一些关于agent的基础认知内容,如果已有了解,可以只看加粗重点内容后,快进到下一章节。
认知基础一:给agent下定义没必要,统一讲agentic systems更合适。
对于什么是agent,行业目前没有一致的定义。
OpenAI 给出的定义是:
Agen是能代表你独立完成任务的系统。
而在Anthropic 看来:
1、能在较长时间内通过LLM 独立、动态的指导其自身流程和工具使用,并完成复杂任务的自主系统也就是agent;
2、通过预定义的代码路径编排 LLM 和工具的workflow;
这些及其变体归类都是“agentic systems”。
对于两大巨头观点,LangChain觉得,OpenAI的定义太模糊,虽然指出了方向,但没办法指导落地。Anthropic 虽然也把Workflow与agent做了二元对立不可取,但整个定义更加精准与技术,并且引入“agentic systems”概念,比较合适。现实生活中,我们所接触的大部分都是将Workflow与agent结合起来的“agentic systems”。
认知基础二:构建一个可落地agent的难点在于合适的大模型与准确的上下文。
做agent不难,但做一个能落地、高可靠性的agent很难,没有人会看了一个 Twitter广告,就把一个demo级的agent 用在自家的核心业务。
Langchain曾经围绕agent落地做过一个调查,发现影响其落地的最大桎梏在于“性能质量”,而性能质量瓶颈的来源是大模型。
 4.22-2.png
4.22-2.png
更进一步拆分,大模型为什么会出错?原因有两个:(a) 模型不够好;(b) 传递给模型的上下文错误(或不完整)。
通常来说,第二种情况更为多见,具体可以细分为:
消息输入不完整或简短
用户输入模糊
无法使用正确的工具
工具描述不佳
未传递正确的上下文
工具响应格式不佳
总之,要想agent效果好,合适的上下文少不了,任何影响你给大模型传递精准内容的框架都是歧路。
认知基础三:广告——LangGraph 是什么
LangGraph 是一个用于构建agentic systems的事件驱动框架, 同时支持函数式 API 和底层事件驱动 API,并提供了 Python 和 TypeScript 两种版本。 它有两种最常见的使用方式:使用声明式的、基于图的语法;使用代理抽象(构建在底层框架之上)。
在 LangGraph 中,代理系统可以被建模为节点(node)和边(edge)的组合:
节点代表一个工作单元(例如 LLM 调用、工具调用等)
边代表节点之间的转移关系
这些节点和边其实就是普通的 Python 或 TypeScript 函数。因此:图的结构是声明式定义的,但图内部的逻辑是命令式的代码。边可以是固定的,也可以是条件式的,因此即使整体结构是声明式的,但图的路径可以是完全动态的。
另外LangGraph 内置了持久化机制,支持:容错机制、短期记忆、长期记忆
这个持久化层还支持“人类参与在环”“human-in-the-loop”与“人类监督在环”“human-on-the-loop”两种交互模式,例如:中断(interrupt)、审批(approve)、恢复(resume)、回溯(time travel)
LangGraph 内置了对流的支持:令牌、节点更新和任意事件。
LangGraph 还与LangSmith无缝集成,支持调试、评估与可观察性(observability),帮助开发者监控和优化agentic systems的行为。
02
一个优秀的Agentic Frameworks应该是什么样?
(1)同时支持workflow、agent
大多数框架都提供了高级的agents抽象。有些框架也会对常见Workflows提供一些封装。
LangGraph 支持workflows、agents 以及介于两者之间的任何内容, 一个可用于生产的框架也需要同时支持这两者。
具体实践中如何选择workflow还是agent,我们需要考虑两个平衡:
第一,可预测性 vs 自主性(Predictability vs Agency)。Agent很聪明省事,但是往往意味着不可预测。
第二,门槛高低与能力上限(Low Floor vs High Ceiling)。workflows上限高,但门槛也高。
(2)同时支持声明与非声明式
除了workflow还是agent,框架还可以分为声明式 和非声明式也就是命令式(Declarative vs Non-Declarative)。
大多数人会把 LangGraph 描述为一个声明式框架,但其实在LangGraph ,虽然节点与边之间的连接是通过声明式方式完成的,但节点和边本身其实就是普通的 Python 或 TypeScript 函数。因此,LangGraph 更像是声明式与命令式的混合体。此外,LangGraph 实际上还支持声明式以外的其他 API,比如函数式 API 和事件驱动 API。
很多人觉得LangGraph 像 TensorFlow(一个声明式深度学习框架),而像 Agents SDK 则像 PyTorch(命令式深度学习框架)。但这个比喻并不准确。像 Agents SDK(包括早期的 LangChain、CrewAI 等)其实既不是声明式,也不是命令式 ——只是一些抽象层。
(3)有抽象能力,但也能被细粒度控制
大多数代理框架都包含一个agent抽象。它们通常以包含提示、模型和工具,以及一些参数。随着参数不断增加,最后你会发现这个类中有一堆控制各种行为的配置项,所有逻辑都被隐藏在类内部。如果你想查看这个agent到底做了什么,或者想要修改行为逻辑,你必须深入类的源码,手动更改底层代码。
这些抽象最终会让你非常难以理解或控制 LLM 在每一步到底接收了什么上下文内容,而这会造成严重问题。
LangChain也是经历了惨痛的教训才明白这一点。早期 LangChain 过度封装了逻辑,让开发者上手很快,但也难以精细控制。
所以,LangChain看来,更好的办法是像 Keras 那样对待agent抽象 —— 作为一个入门级的高层接口,能让开发者快速开始,但它必须建立在一个底层框架之上,这样在需要时才能“突破抽象层”,完成细粒度控制。
(4)优秀的多代理(Multi Agent)通信机制
通常情况下,一个agentic system中会包含多个agent。协同它们的关键在于组织其通信。
实现方式有很多。例如 “handoffs(任务交接)” ,它是 Agents SDK 中的一个代理抽象。
但有时,这些代理的最佳沟通方式可能是workflow。
这是Anthropic 博客文章中的所有工作流程图,你可以把图中的 LLM call替换成不同的agent。
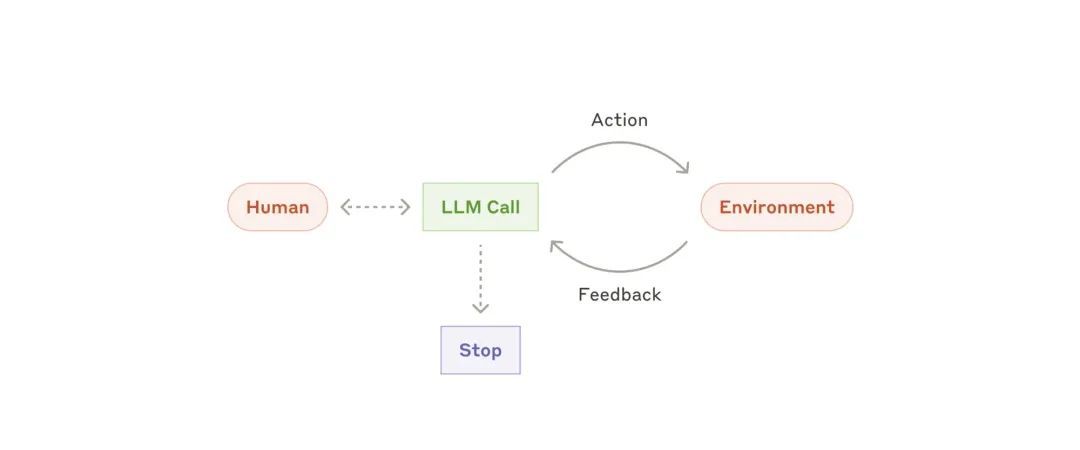 4.22-3.jpeg
4.22-3.jpeg
(5)更多的功能支持
为开发者提供实用的抽象、降低上手门槛很重要,但很可惜,这也成了市面上很多框架的唯一价值。LangGraph 为了避免这个情况,还会额外增加以下设计:
短期记忆:多轮(例如聊天)是常见交互,LangGraph 提供了生产可用的持久化存储机制,支持“对话线程”等多轮体验。
长期记忆:这个功能探索还在早期阶段,目前LangGraph 已经支持跨线程记忆,也具备生产可用的存储层。长期来看,“从经验中学习”的能力(例如:跨会话记住事情)会是发展的关键。
人类参与在环(Human-in-the-loop):很多代理系统如果允许人类参与某些决策环节,效果会更好,例如:用户反馈、工具调用审批、修改调用参数,LangGraph 全都提供内建支持。
人类监督在环(Human-on-the-loop):除了让用户“在运行时参与”,我们还可能希望用户在事后查看代理的完整执行轨迹,甚至“回到过去某一步重新运行”。我们称之为“人类监督在环”,LangGraph 也原生支持这一模式。
流式处理(Streaming): agent通常运行时间较长,因此向用户及时推送执行状态对体验非常重要。LangGraph 原生支持以下流式输出:Token 流、节点状态流、自定义事件流
调试与可观察性(Debugging / Observability): 上面提到,我们需要确保每一步传给 LLM 的上下文是对的, 因此,能观察每一步的输入输出非常关键。LangGraph 可与 LangSmith 无缝集成,提供调试与可观察性支持。
容错机制(Fault Tolerance): 在构建分布式应用时,容错能力是基础要求。LangGraph 提供持久化工作流和可配置重试机制。
优化(Optimization): 在优化代理系统时,与其手动修改 prompt,有时更好的方式是:定义一个评估数据集,然后自动优化代理策略。 LangGraph 暂未内建此功能, 目前最适合这类需求的框架是 dspy。
基于以上认知,不难发现,用好框架的基础,是了解底层代码。对底层原理的错误认知是常见的报错来源。
03
OpenAI 的看法有什么错误?
这两年,很多人会说,agent虽然还不够智能,但长期一定会取代workflow,开发者只要会简单的工具调用就能搞定一切。
这个说法,其实不完全正确。
Agent的工具调用能力提升,对某些任务,工具循环代理也确实足够(微调过模型,或者任务与大模型本身的 SOTA方向高度一致,比如编程);但这种情况不多。
而且,“输入什么 → 输出什么”的原理永远有效,垃圾输入 = 垃圾输出;对于有些任务,工作流可能更简单、更便宜、更高效;多数真实应用中,生产级agentic system是“工作流 + 代理”的混合体。
所以OpenAI的立场最大的问题就是,结论建立在错误的二分法之上,把不同“代理框架”混为一谈,过度夸张抽象的价值。
 4.22-4.jpeg
4.22-4.jpeg
具体到OpenAI的这个博文,8行文字,可以挑出8个错误:
1、LangGraph 并不是完全声明式的框架
2、“当工作流变得更加动态和复杂时,这种方法很快就会变得繁琐和困难”——这段话的本质问题不是“声明式 vs 非声明式”,而是“workflow vs agent”,用户可以在Agents SDK 中以声明式图的方式表达代理逻辑。
3、workflow根本不需要那么多的动态性或复杂性,也不是所有场景都要用workflow或者agent。
4、Agents SDK 不是命令式框架,它是抽象层。而它的这些抽象,本质上也是一种领域特定语言。
5、 Agents SDK 里能做的事,在框架里都能做,不存在框架不灵活。
6、Agents SDK 不存在“更代码优先”。
7、Agents SDK并不是使用熟悉的编程结构就搞定的,你得学习一整套新抽象。
8、更动态、适应性更强的代理编排,这还是和声明式 vs 非声明式无关,依旧是“workflow vs agent”的问题。
总而言之,就是混淆了“声明式与命令式”与“代理抽象”,以及“工作流与代理”之间的区别,并且低估了生产级agentic system的构建难度。
04
写在最后
我们是Zilliz,在 GitHub 上取得超过34,000star的开源向量数据库Milvus的原厂团队。
文中LangChain提到的长期记忆、短期记忆以及更优的模型上下文输出,采用开源的向量数据库Milvus或者我们基于Milvus推出的全托管多云向量数据库服务Zilliz Cloud,均可以为您带来产品级的专业服务。
目前Milvus已在全球覆盖超一万家企业用户,下载和部署次数超过了 1 亿次,Zilliz Cloud则已支持 AWS、GCP 和 Azure 、阿里云、腾讯云等主要云平台,在 20 多个国家和地区可用。


