



Late Chunking×Milvus:如何提高RAG准确率
背景:
在RAG应用开发中,第一步就是对于文档进行chunking(分块),高效的文档分块,可以有效的提高后续的召回内容的准确性。而对于如何高效的分块是个讨论的热点,有诸如固定大小分块,随机大小分块,滑动窗口重新采样,递归分块,基于内容语义分块等方法。而Jina AI提出的Late Chunking从另外一个角度来处理分块问题,让我们来具体看看。
Late Chunking是什么:
传统的分块在处理长文档时可能会丢失文档中长距离的上下文依赖关系,这对于信息检索和理解是一大隐患。即当关键信息散落在多个文本块中,脱离上下文的文本分块片段很可能失去其原有的意义,导致后续的召回效果比较差。
以Milvus 2.4.13 release note为例,假如分为如下两个文档块,如果我们要查询Milvus 2.4.13有哪些新功能?,直接相关内容在分块2里,而Milvus版本信息在分块1里,此时,Embedding 模型很难将这些指代正确链接到实体,从而产生质量不高的Embedding。
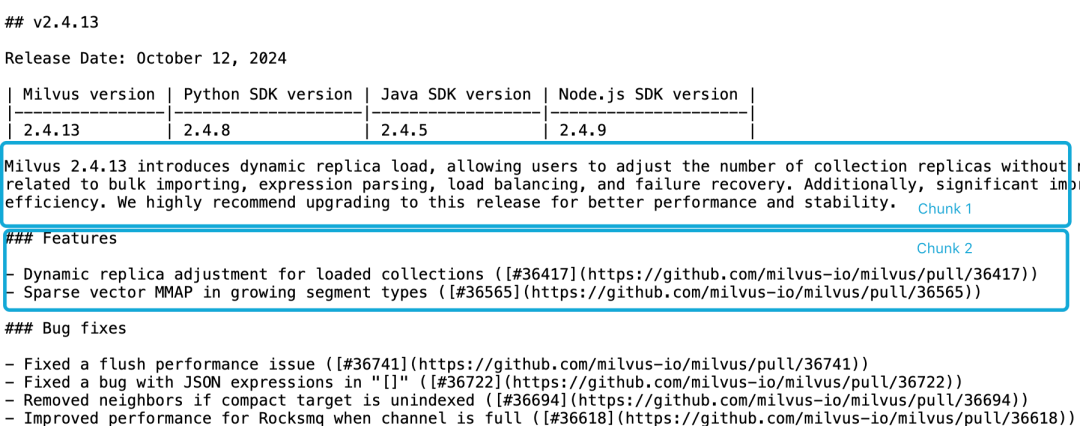 1.png
1.png
由于功能描述与版本信息不在同一个分块里,且缺乏更大的上下文文档,LLM 难以解决这样的关联问题。尽管有一些启发式算法试图缓解这一问题,如滑动窗口重新采样、重叠的上下文窗口长度以及多次文档扫描等,然而,像所有启发式算法一样,这些方法时灵时不灵,它们可能在某些情况下有效,但是没有理论上的保证。
传统的分块采用一种预先分块的策略,即先分块,再过 Embedding 模型。首先依据句子、段落或预设的最大长度等参数对文本进行切割。然后Embedding 模型会对这些分块逐一进行处理,通过平均池化等方法,将 token 级的 Embedding 聚合成单一的块 Embedding 向量。而Late Chunking则是先过 Embedding 模型再分块(late的含义就是在于此,先向量化再分块),我们先将 Embedding 模型的 transformer 层应用到整个文本,为每个 token 生成一个包含丰富上下文信息的向量表示序列。然后,再对这些 token 向量序列进行平均池化,最终得到考虑了整个文本上下文的块 Embedding。
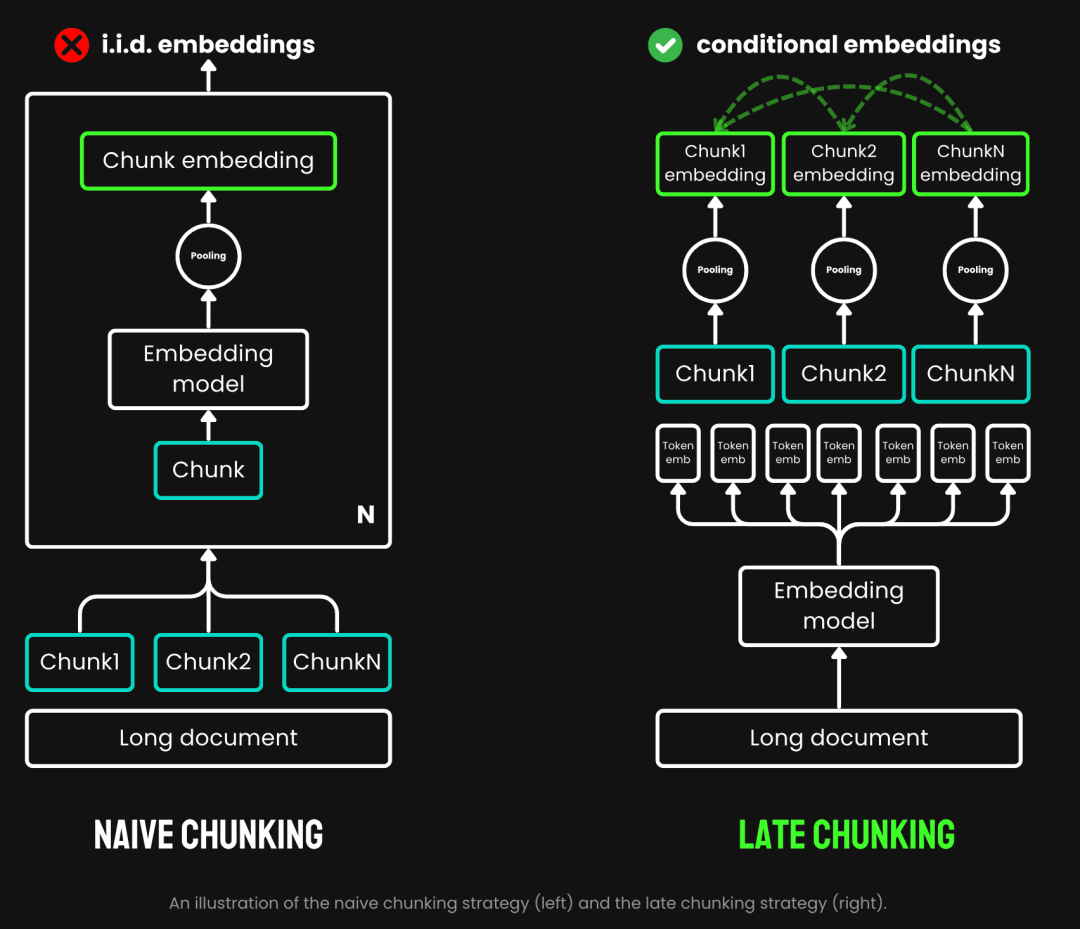 2.png
2.png
(图片来源https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
Late Chunking生成的块Embedding,每个块都编码了更多的上下文信息,从而提高了编码的质量和准确性。我们可以通过支持长上下文的 Embedding 模型,如 jina-embeddings-v2-base-en,它能够处理长达8192个token 的文本(相当于 10 页 A4 纸),基本满足了大多数长文本的上下文需求。
综上所述,我们可以看到Late Chunking在RAG应用中的优势:
提高准确性:通过保留上下文信息,与简单分块相比,Late Chunking为查询返回了相关度更高的内容。
高效的LLM调用:Late Chunking可以减少传递给LLM的文本量,因为它返回的分块更少且相关度更高。
测试Late Chunking:
Late Chunking基础实现
函数sentence_chunker对于原始文档以段落进行分块,返回分块内容以及分块标记信息span_annotations(即分块的开始和结束标记)
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
函数 document_to_token_embeddings 通过模型 jinaai/jina-embeddings-v2-base-en 的模型以及tokenizer,返回整个文档的Embedding。
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096):
tokenized_document = tokenizer(document, return_tensors="pt")
tokens = tokenized_document.tokens()
outputs = []
for i in range(0, len(tokens), batch_size):
start = i
end = min(i + batch_size, len(tokens))
batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()}
with torch.no_grad():
model_output = model(**batch_inputs)
outputs.append(model_output.last_hidden_state)
model_output = torch.cat(outputs, dim=1)
return model_output
函数 late_chunking 对整个文档的Embedding以及原始分块的标记信息span_annotations进行分块。
def late_chunking(token_embeddings, span_annotation, max_length=None):
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation):
if (
max_length is not None
):
annotations = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start < (max_length - 1)
]
pooled_embeddings = []
for start, end in annotations:
if (end - start) >= 1:
pooled_embeddings.append(
embeddings[start:end].sum(dim=0) / (end - start)
)
pooled_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputs
如使用模型jinaai/jina-embeddings-v2-base-en进行Late Chunking
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
与传统Embedding方法对比
我们以milvus 2.4.13 release note 这一段内容为例,
Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.
This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.
Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.
We highly recommend upgrading to this release for better performance and stability.
分别进行传统Embedding,即先分块,然后进行Embedding。以及Late Chunking方式Embedding,即先Embedding,然后再分块。然后,把 milvus 2.4.13 分别与这两种Embedding方式的结果进行对比
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
从结果来看,词语 milvus 2.4.13 与分块文档Late Chunking结果相似度高于传统Embedding。原因是Late Chunking先对于全部文本段落进行Embedding,使得整个文本段落得到了 milvus 2.4.13 信息,进而在后续的文本比较中显著的提高了相似度。
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
Milvus中测试Late Chunking
导入Late Chunking数据到Milvus
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
查询测试
我们定义cosine相似度查询方法,以及使用Milvus原生查询方法分别对于Late Chunking进行查询。
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
从结果来看,两个方法返回内容是一致的,这表明Milvus中对于Late Chunking查询结果是准确。
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['\n\n### Features\n\n- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))\n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['\n\n### Features\n\n- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))\n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
总结:
我们介绍了Late Chunking产生的背景,基本概念以及基础实现,然后通过在Mivlus测试发现,Late Chunking效果不错。总体来看,Late Chunking在准确性、效率和易于实施方面的结合,使其成为RAG应用的一个有效的方法。
参考文档:
https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
https://jina.ai/news/late-chunking-in-long-context-embedding-models/
https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
代码可通过链接获取(在 aws g4dn.xlarge 机器上运行):https://pan.baidu.com/s/162p_pwIGw-yA5ogMmSSrsQ?pwd=1234 提取码: 1234
 臧伟
臧伟

