有多少人因为token爆炸,取订了Claude Code
最近,无论国内海外开发者,一半都在吐槽Claude Code,另一半则打算改完手里的bug再吐槽Claude Code。
国内用户的不满集中在无端账号封禁上,而海外用户则对Code 功能的 Token 消耗过快怨声载道。
更关键的是,从技术层面来看,降低 Token 消耗对 Claude 并非难事,但它却选择单一的 grep 方案做代码检索,由此产生了大量不必要的 Token 浪费
为此,我们前段时间开源了Claude Context—— 通过 MCP模式,让 Claude Code 等 AI IDE 具备一键搞定代码上下文检索的能力,可直接减少约 40% 的 Token 消耗。
但这个方案,也在各大技术论坛引发了激烈讨论。
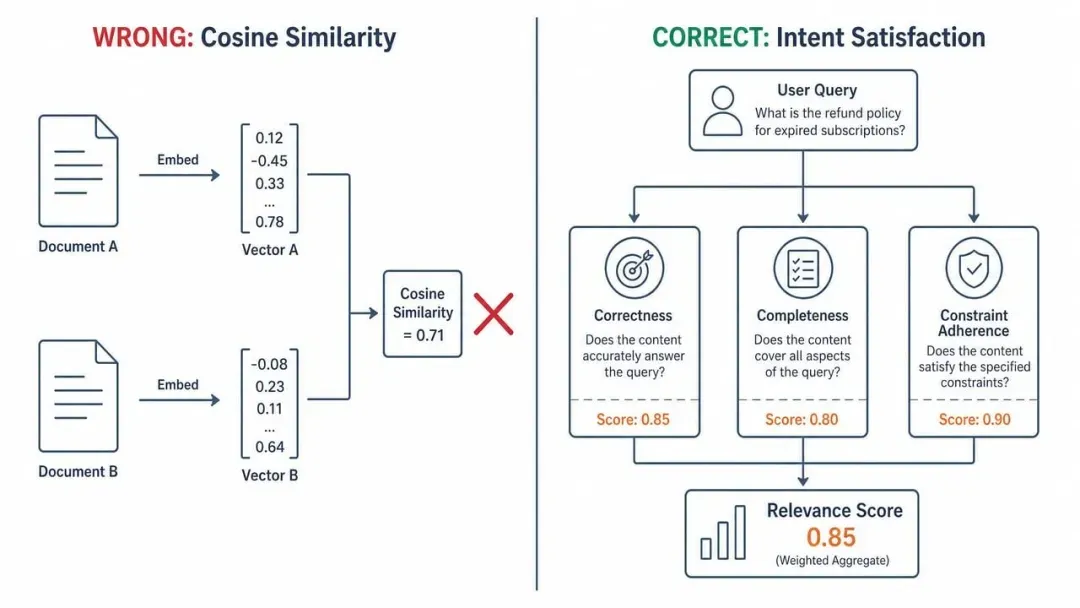
有人认为grep足够用,引入向量数据库和embedding,会导致过度工程化!
也有人认为,grep 只能字面匹配,根本理解不了代码语义,Claude Context 能大幅提升检索精度和效率。
双方观点看似各有道理,不如用实测数据一较高下
01 实验设计思路
对比双方:
Baseline 方法:纯 grep + read + edit 工具的基础 Agent
增强方法:基础 Baseline 工具 + Claude Context MCP 的增强 Agent
评估指标:
检索质量:F1-Score、精确率、召回率
效率指标:Token 消耗、工具调用次数
成本效益:单任务处理成本
实验条件(控制变量)
为排除无关变量干扰,两种方法使用完全一致的实验环境:
相同 LLM:GPT-4o-mini
相同数据集:Princeton NLP 的 SWE-bench Verified 数据集(含 500 个经专业审查的高质量样本,专为评估 AI 解决真实软件工程问题设计)
相同框架:ReAct Agent 框架
相同任务:30 个难度适中(15-60 分钟)、标准化(每个任务需修改 2 个文件)的任务实例
每种方法均运行 3 轮独立实验,取平均值后进行对比,总计完成 6 次完整测试。
 28-1.webp
28-1.webp
02 实验结果
实验结果直接验证了我们的初始设想 ——Claude Context 的增强方法在效率、成本、精度上全面优于纯 grep 的 Baseline 方法。核心结论有三
Token 消耗大幅降低:相比 Baseline,增强方法 Token 消耗减少近 40%,单个任务平均节省 28,924 个 Token;重度 AI 编程用户每月可节省几十到几百美元 API 费用;
工具调用更高效、响应更快:工具调用次数减少超过 1/3,避免了无效操作的资源浪费;原本 5 分钟的代码定位任务,现在 3 分钟即可完成;
检索精度更优:精准定位核心代码上下文,让后续的AI生成更精准
 28-2.webp
28-2.webp
03 案例解读,纯 grep 的缺陷是什么?
这里选择了两个案例,分析他们的日志,来说明为什么纯 grep 方法效率低下。
案例一:Django YearLookup Bug
Issue 地址为 https://github.com/django/django/pull/14170
问题描述: Django 框架中,
YearLookup查询优化破坏了__iso_year过滤功能。当使用__iso_year过滤器时,YearLookup类错误地应用了标准的 BETWEEN 优化,这对日历年有效,但对 ISO 周编号年无效。
Baseline grep 方法的过程日志分析:
关键问题: 文本搜索专注于错误的组件(ExtractIsoYear 注册),而不是实际的优化逻辑(YearLookup 类)。
Claude Context 方法的过程日志分析:
关键成功: 语义搜索立即理解了"YearLookup"作为核心概念,找到了需要修改的确切类。
效率对比:
Baseline 方法:8 次工具调用,消耗 130,819 tokens,0% 命中率
Claude Context:3 次工具调用,消耗 9,036 tokens,50% 命中率
节省了 93% 的 Token!
案例二:Xarray swap_dims Bug
Issue 地址为 https://github.com/pydata/xarray/pull/6938
问题描述: Xarray 库的
.swap_dims()方法意外修改了原始对象,违反了不可变性期望。在某些情况下,.swap_dims()修改原始对象而不是返回新对象。
Baseline grep 方法的过程日志分析:
关键低效: 使用了大量的 list_directory 和 read_file 操作,而不是专注于相关方法。
Claude Context 方法的过程日志分析:
关键成功: 语义搜索立即定位了实际的 swap_dims() 实现并理解了功能上下文。
效率对比:
Baseline 方法:11 次工具调用,消耗 41,999 tokens,50% 命中率
Claude Context:3 次工具调用,消耗 15,826 tokens,50% 命中率
节省了 62% 的 Token!
04两种方法的工作流程对比
我们可以用流程图来直观对比两种方法的差异:
Baseline grep 方法的工作流程
 28-3.webp
28-3.webp
Claude Context 语义搜索工作流程
 28-4.webp
28-4.webp
不难发现,纯grep 的局限性源于其 “字面匹配” 的本质,这带来了三大致命缺陷
信息过载:现代代码库动辄数万文件,grep 搜索结果中 99% 为无关噪音,AI 易被洪流淹没;
语义盲目:仅匹配字符组合,无法理解代码功能 —— 例如找不到
compute_final_cost()与calculate_total_price()的语义关联;上下文失忆:仅返回匹配行,缺失函数所属类、依赖关系等关键上下文,AI 难以判断代码作用。
也是针对这三大局限,Claude Context 针对三大核心能力做了突破
智能过滤:通过向量相似度排序,将最相关的代码片段置顶,排除无关干扰;
概念理解:基于 embedding 技术理解代码语义,即使函数名不同,只要功能相似就能精准匹配;
上下文召回:每个搜索结果均包含完整的代码上下文(类、函数、依赖),让 AI 像人类程序员一样理解代码逻辑。
尾声
Claude Context不仅适用于Claude Code,同样适用于 Codex、 Gemini CLI、Cline在内几乎所有AI coding产品,欢迎大家多多体验与反馈。
项目地址: https://github.com/zilliztech/claude-context
实验详情: 完整的实验数据、代码和复现方法都在项目的 evaluation/ 目录中开放。
 张晨
张晨Cheney Zhang is an accomplished Algorithm Engineer at Zilliz.