Claude通过Cowork实现模型主动记忆,要如何复现?我们还需要RAG吗?
上周,Claude的一个能力更新爆料,让不少RAG从业者的天塌了。
简而言之,Anthropic正在为 Claude Cowork 增加一个类似知识库的能力,让模型交互从只能做单次交互,转向可以完成多对话、多任务之间持续记忆复用。
具体来说,模型会选择性的记住我们每次与它交互的过程,以及产生的结论,这些数据可以被实时写入、快速检索、并且以短期记忆、用户属性、长期记忆等形式被分门别类的保存,然后被主动复用在下一次的会话中。
比如,你让AI写一个文章,不用反复输入相同提示词,它会自动知道你的审美偏好;或者你让AI写一个你们公司的企业发展介绍,AI直接调取历史交互内容,就能自动完成撰写。
那么,当模型侧进化出深度记忆与历史数据检索能力之后,我们是否还需要RAG以及向量数据库?与此同时,我们要如何复刻打造自己的开源Claude Cowork记忆?
本文将重点回答这两个问题。
01
如何理解Claude Cowork的记忆功能?
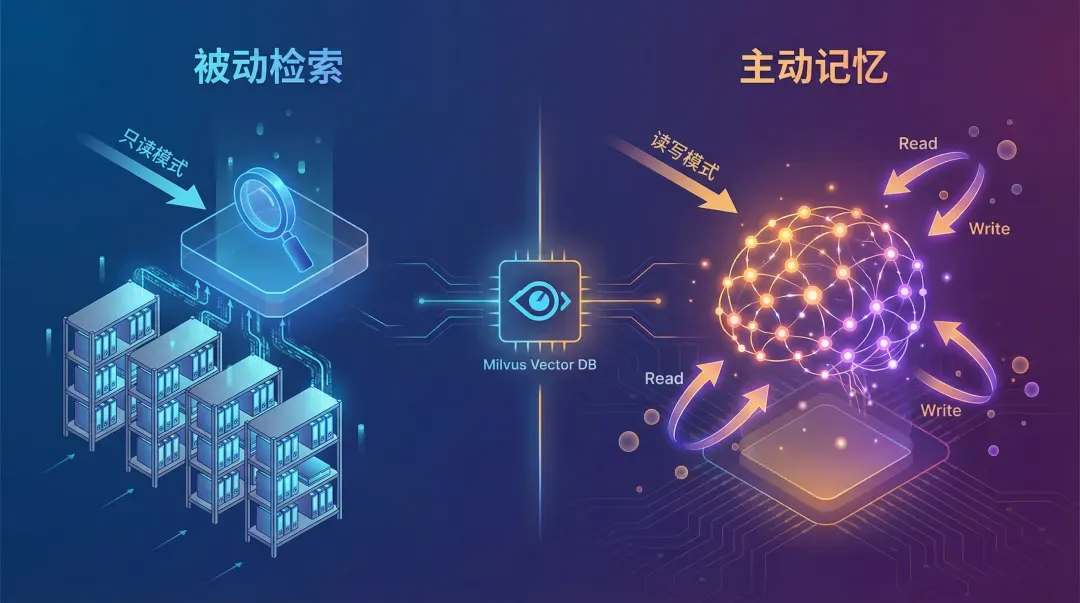 640.webp
640.webp
02
Agent Memory如何搭建
Cowork具体如何运作的,目前尚未公开,但是此前曾有开发者对Claude 本身的记忆模块做了拆解,我们可以从中找到一些蛛丝马迹。
Claude 采用长期记忆 + 按需工具检索的动态架构,仅在需要时调取历史上下文,平衡细节深度与效率。其上下文结构为:[0]系统指令(静态)→ [1]用户记忆 → [2]对话历史 → [3]当前消息。两者的核心差异体现在 对话历史的检索方式和用户记忆”的更新逻辑。
 640-1.webp
640-1.webp
对话历史(Conversation History)方面,Claude 未采用固定摘要注入,而是通过三个互补组件动态调取历史,仅在模型判断需要时触发,避免无效 token 消耗。
这套组件中,比较值得研究的是conversation_search,能在模糊表述、多语言查询等场景依然能实现命中,背后应该使用了语义层面的匹配能力(常见实现是 embedding 检索,或“翻译/规范化 + 关键词/混合检索”的组合)。
整体来看,Claude 这套按需检索系统的特点则在于
非自动触发:工具调用由 Claude 自主判断,如用户提 “上次聊的项目” 时,触发conversation_search。
细节保留:检索结果包含助手回复片段(ChatGPT 摘要仅用户消息),适合需要上下文深度的场景;
效率优势:无需每次注入所有历史,减少无关 token 消耗。
缺点则在于,一旦引入按需检索,系统复杂度上升(索引构建、查询、排序、可能的重排),端到端延迟不如预计算注入可控;同时模型还必须学会判断何时该检索,判断失误就会丢上下文。
另外,与Claude 思路形成对比的是ChatGPT的记忆管理模式,ChatGPT 未采用传统的向量数据库(RAG)或全量对话存储而是通过四个分层组件将记忆提前注入每次对话的上下文,在保证个性化的同时控制计算成本。
其中,用户长期记忆(User Memory),是长期、可编辑的核心记忆,用于记录用户稳定属性(,如姓名、职业目标、过往经历、项目成果、学习偏好),每次对话都会强制注入。其更新方式包括显式更新(用户通过 “记住这个”“从记忆中删除” 等指令直接管理)以及隐式更新(模型检测到符合 OpenAI 标准的事实如姓名、职位且用户默认同意时,自动添加。)
会话元数据(Session Metadata)指的是短期、非持久化记忆,仅在会话启动时注入一次,会话结束后销毁,主要用于让模型适配当前场景(如移动端简化回复格式),不影响长期记忆。其内容聚焦用户当前使用环境,包括:设备信息;账号属性(订阅等级如 ChatGPT Go、账号年龄、使用频率);行为数据(近 1/7/30 天活跃天数、平均对话长度、模型调用分布如 49% 用 GPT-5)。
当前会话消息(Current Session Messages)则是一个滑动窗口上下文层,用于维持当前会话连贯性的短期缓存,会存储全量对话内容。当超出 token 上限时,自动 “滚除” 最早的消息,但长期记忆和近期对话摘要不受影响。
两者的核心区别在于近期会话,ChatGPT搭建了一个轻量化跨会话层,用于替代传统 RAG 的全量检索,每次对话均注入。这一层仅总结用户消息(不包含助手回复);数量有限(约 15 条),仅保留近期兴趣,不存储细节;整个过程无需嵌入计算或相似度搜索,可以显著降低延迟和 token 消耗。
03
向量数据库如何解决 Agent Memory的三个工程问题
当记忆系统从只读变成可写,会遇到三个具体的工程问题。
第一个问题,需要记住什么?
不是所有操作都需要记录。用户创建了一个临时文件,五分钟后删掉了。这个操作要不要存?
这涉及到重要性判断。但重要性的标准是什么?
按时间:最近的操作更重要
按频率:被多次访问的文件更重要
按类型:某些文件类型天然更重要(比如项目配置文件 vs 临时缓存)
问题是这些标准会冲突。用户上周创建的文件,今天突然频繁修改,它的重要性是按创建时间算还是按修改频率算?
技术上,向量数据库可以提供一些工具。比如 Milvus 支持给数据设置 TTL(Time To Live),自动删除过期数据。也可以用衰减函数,让旧数据的权重随时间降低。
但这些都是辅助手段。重要性的判断标准,还是得应用层自己定义。
第二个问题是,怎么分层存储
当任务周期变长、数据量变大,分层存储就成了刚需。
这里的难度有两方面,如何判断内容重要性?我们可以基于一个小模型做判断,可以基于规则做相对暴力的判断,比如
按时间切分:超过 30 天的数据自动降冷
按访问频率:连续 7 天没被访问的数据降冷
按用户标注:用户手动标记重要文件,永远保持热状态
做完了判断之后,接下来就是分层存储。
Milvus 支持冷热数据分层。热数据以及知识图谱放内存,冷数据放磁盘或 S3。
第三个问题在于如何确定写入频率与速度。
传统 RAG 系统的写入是批量的、离线的。今天收集一批文档,晚上跑个脚本建索引,明天用户就能查到。
但agent memory不行,用户每操作一次,就得实时写入一条记录,如果写入慢了,下一次对话就读不到刚才的操作历史。
这对向量数据库的实时写入能力要求很高。问题是:实时写入和检索精度之间有权衡。
向量索引需要时间构建,如果每写入一条数据就重建索引,成本太高,如果先攒一批再建索引,又会导致新写入的数据检索不到。
Milvus 采用了流式写入和增量索引更新的方案可以很好的解决这个问题。新数据先写入内存缓冲区,来支持更高频的实时写入,并在秒级被检索到。达到一定阈值后,再批量更新索引。这在写入速度和检索性能之间找到了平衡。
 尹珉
尹珉Zilliz 黄金写手