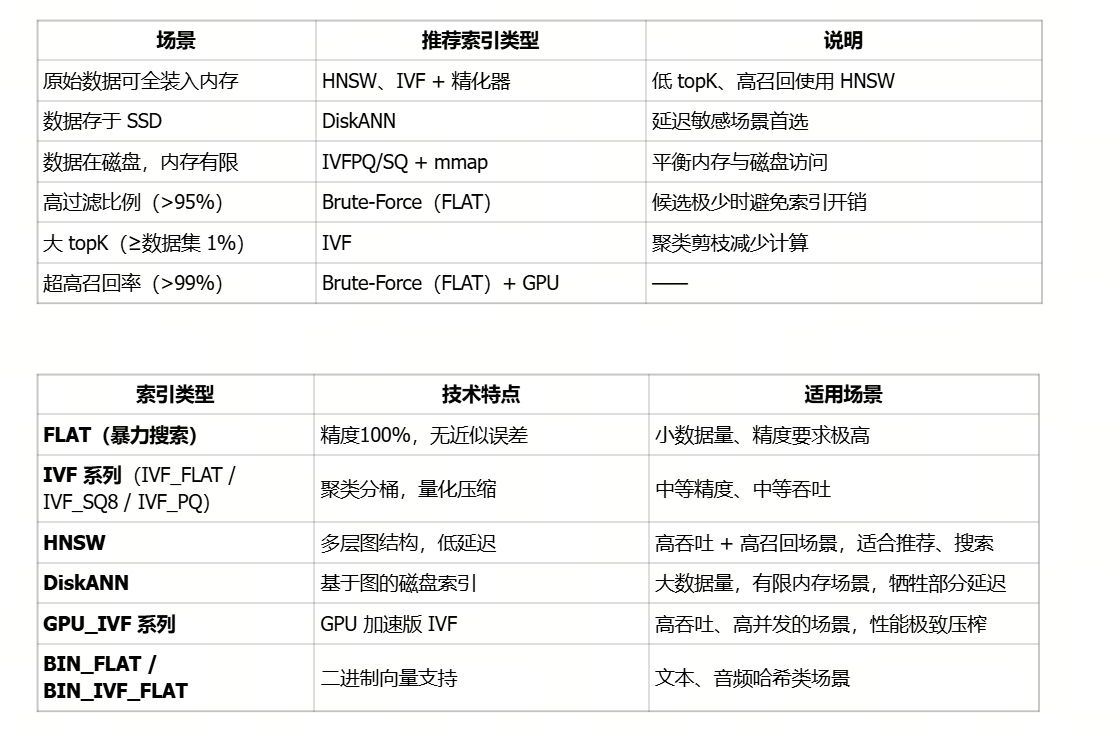
索引选不对,成本贵十倍!一文读懂向量索引选型

在使用 Milvus 构建向量检索系统的过程中,很多开发者常常会在“该选哪种索引”这一步卡壳。
是要精度优先的 FLAT,还是速度更快的 IVF_PQ?是适合实时检索的 HNSW,还是适合离线大规模数据的 DiskANN?
不同索引适配的场景差异很大,选错了不仅影响性能,还可能造成资源浪费。
那么该如何对其进行选择呢?本篇文章,带你十分钟读懂不同条件下的索引选型逻辑。
01 向量索引科普
在思考如何挑选索引之前,我们需要知道什么是索引。索引的本质是基于数据的规律,所构建的一种用于加快查找速度的数据结构。
在向量检索中,索引能显著提升查询效率,但也会带来一定的预处理时间开销、额外的存储空间占用,以及在搜索过程中更高的内存消耗。此外,使用索引相对于暴搜而言,通常召回率会出现一定的下降,虽然影响有限,但在对精度有要求的场景中仍需关注。
在 Milvus 中,索引是以字段为单位进行构建的,不同数据类型支持的索引类型也不同。作为一款面向向量检索场景设计的专业数据库,Milvus 在向量搜索与标量过滤两个方面均提供了丰富的索引选项,以提升整体检索性能。
下表展示了字段类型与可用索引类型的对应关系:

02 向量索引结构解析
首先,我们必须明白一个前提,做索引选型时,我们必须综合考虑底层数据结构、内存占用和性能需求等因素。
如图所示,Milvus 中的每种索引类型都由三部分组成:数据结构(用于粗过滤)、量化器(用于提升计算效率)和精化器(用于提升结果精度)。其中,量化器和精化器虽然是可选项,但整体性价比较高。
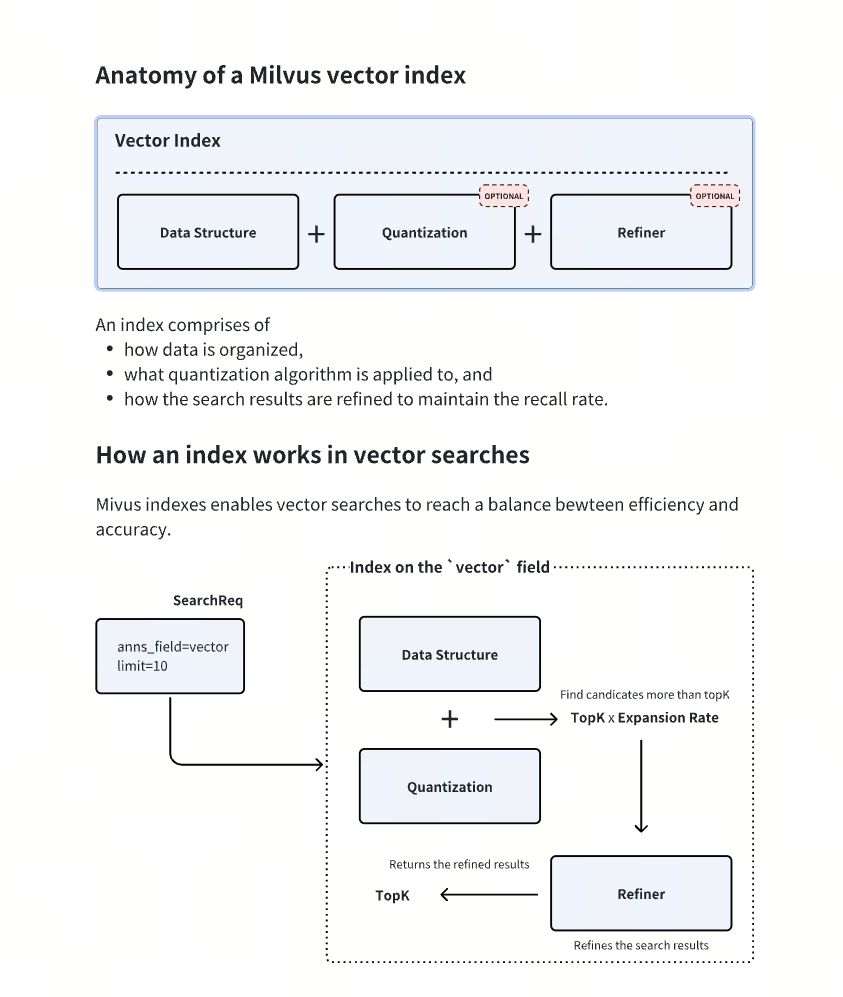
接下来,我们会对这三部分做出依次解读:
数据结构
数据结构是索引的基础层,常见结构包括:
(1)倒排文件(IVF)
IVF 系列索引通过质心聚类将向量划分为多个桶。若某桶的质心与查询向量接近,可合理假设该桶内的向量也可能接近查询向量。基于此前提,Milvus 仅扫描质心接近查询向量的桶内向量,而非整个数据集,从而在保持可接受精度的同时,降低计算成本。
适合需要高吞吐量的大规模数据集。
(2)图结构(Graph-based)
例如 HNSW(Hierarchical Navigable Small World),构建了多层图结构,每个向量与其近邻相连。查询过程从上层粗粒度图开始逐层向下,最终定位最邻近向量,实现对数级搜索复杂度。
适合高维空间和低延迟场景。
量化(Quantization)
量化通过对向量进行粗略表示来减少内存与计算开销:
标量量化(如 SQ8):将每个维度压缩为一个字节(8 位),相比 32 位浮点数可节省 75% 内存,同时保留合理准确性。
乘积量化(PQ):将向量分成子向量,用码本进行聚类编码,实现 4–32 倍压缩比,适合内存受限场景,代价是召回率略有下降。
精化器(Refiner)
由于量化会导致信息损失,为保持召回率,量化通常会多返回候选结果,供精化器以更高精度重新筛选出 topK。例如,FP32 精化器会使用 32 位浮点数重新计算距离,以替代使用量化向量计算出来的距离。。
这种机制对语义搜索、推荐系统等要求高精度的场景至关重要。
03 如何评估不同索引
(1)性能
评估索引性能时,应平衡建索时间、QPS 与召回率,通常遵循以下规律:
图索引在 QPS 表现上通常优于 IVF;
IVF 更适用于 topK 较大的场景(如 > 2000);
PQ 在相似压缩率下召回率优于 SQ,但 SQ 性能更快;
将索引部分内容存储于硬盘(如 DiskANN)适合超大数据集,但可能出现 IOPS 瓶颈。
(2)容量
容量涉及数据量与可用内存的关系,建议如下:
若原始数据的 1/4 可放入内存,使用 DiskANN 可获得稳定延迟;
若全部数据可放入内存,可使用基于内存的索引 + mmap;
若需最大容量,可结合量化索引与 mmap,牺牲部分精度换取容量。
注意:mmap 并非万能,若大部分数据在磁盘,DiskANN 延迟表现更优。
(3)召回率
召回率与过滤比例密切相关:
过滤比例 < 85%:图索引优于 IVF;
过滤比例 85%–95%:使用 IVF;
过滤比例 > 98%:使用 Brute-Force(FLAT)最准确。
提示:以上为经验规律,实际推荐测试不同索引类型以调优召回率。
(3)性能(按 top-K)
top-K 指每次查询返回的结果数量:
小 topK(如 2000及以下)+ 高召回:图索引更优;
大 topK:IVF 优于图索引;
中等 topK + 高过滤:IVF 表现更佳。
(4)内存占用估算
注:本节包含大量技术细节,若无相关需求可跳过。
索引的内存占用与其数据结构、量化压缩率及是否使用精化器有关。一般来说:
图索引(如 HNSW)内存开销较大,每个向量需存图结构;
IVF 系列因簇内向量较少,内存效率更高;
DiskANN 可将图结构与精化器部分移至磁盘,减少内存压力。
IVF 内存估算(100 万条 128 维向量):
质心:2000 × 128 × 4 字节 = 1 MB
向量分簇:100 万 × 2 字节 = 2 MB
量化压缩(任选其一):
PQ(8 子量化器):8 MB
SQ8(128 维 × 1 字节):128 MB
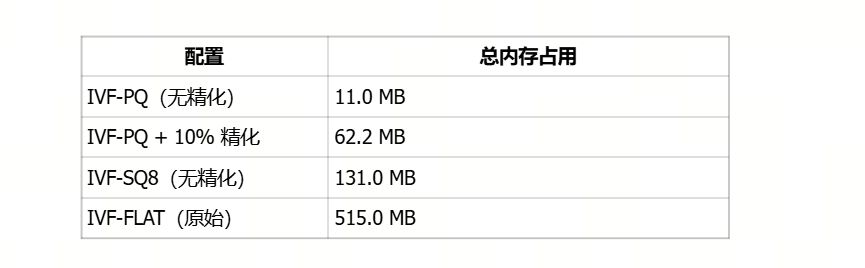
- 精化开销(topK=10,扩展率=5):50 × 128 × 4 = 25.6 KB
图索引内存估算(HNSW)
图结构:100 万 × 32 × 4 字节 = 128 MB
原始向量:100 万 × 128 × 4 字节 = 512 MB
- 总计:640 MB
使用 PQ 压缩:100 万 × 8 字节 = 8 MB
- 总计:128 MB + 8 MB = 136 MB
精化开销:同上为 25.6 KB
(5)其他注意事项
IVF 与图索引适合结合量化器优化内存;
mmap 与 DiskANN 可应对数据量超出内存场景。
其中,DiskANN是基于 Vamana 图结构,通过 PQ 压缩向量,在硬盘上建立可导航索引,适用于十亿级数据集。mmap(内存映射)则支持将磁盘文件映射到内存空间,无需完全加载字段数据即可访问,有效减少 I/O 开销,提升系统容量并保持良好搜索性能。
尾声
最后,如果上文读完还是记不住,以下两张表存起来,帮你立刻搞懂索引选型逻辑!要是还是没学会,欢迎使用zilliz cloud,用AUTO INDEX功能让AI智能帮你选择最合适的索引。