



从BGE到 CLIP,从文本到多模态,Embedding 模型选型终极指南

通过通过将原始输入转换为固定大小的高维向量,捕捉语义信息,embedding(嵌入)模型在构建RAG、推荐系统,甚至自动驾驶的模型训练过程中都产生着至关重要的影响。
即使 OpenAI、Meta 和 Google 等科技巨头,也选择在近些年来,在 embedding 模型的研发上持续加大投入。以 OpenAI 为例,其最新的 text-embedding-3-small生成 1536 维向量,在保持高语义表达能力的同时,实现了更低的延迟和更小的模型体积,适用于对性能敏感的大规模语义检索场景。Meta 则早在 2019 年就推出了 DLRM(Deep Learning Recommendation Model),以 embedding 层为基础构建用户和物品的向量表示,用于广告点击率预测。DLRM 至今仍是支撑 Meta 推荐系统的核心组件,服务于其每天数千亿次的推荐请求。
但要如何选择 embedding 模型?本文将提供一个实用的评估框架,我们可以根据自身需求选择最合适的 embedding 模型。
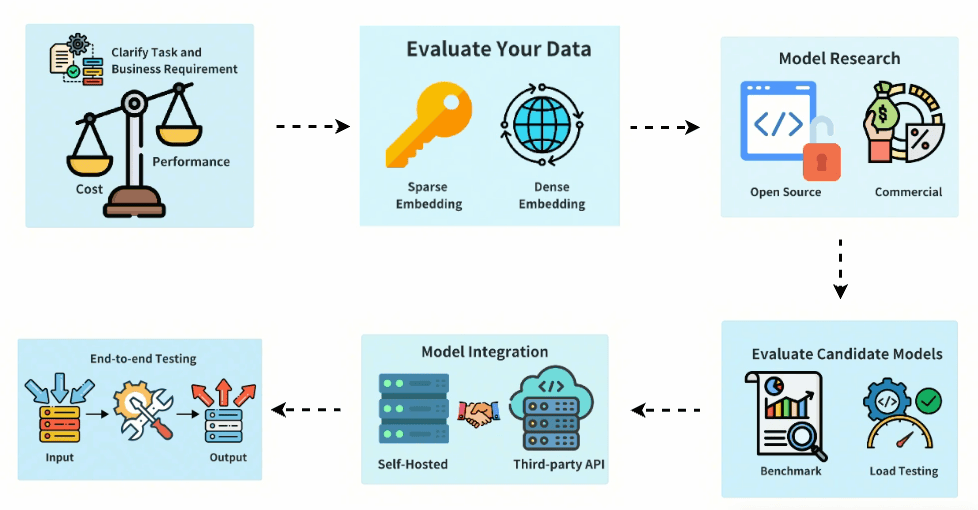
一、明确任务和业务需求
在选择模型前,首先需要明确你的核心目标:
任务类型:你要构建的是语义搜索、推荐系统、分类管道,还是其他类型的应用?不同任务对 embedding 表征信息的方式有不同要求。例如:
语义搜索:需要如 Sentence-BERT 等模型,能够捕捉查询与文档之间的语义细节,使相似概念在向量空间中彼此接近。
分类任务:embedding 需要反映类别结构,相同类别的输入应靠得更近,方便下游分类器区分。常用模型如 DistilBERT 和 RoBERTa。
推荐系统:embedding 需反映用户-物品的关联,可采用如神经协同过滤(NCF)等基于隐反馈训练的模型。
ROI 评估:根据业务上下文权衡性能与成本。对于如医疗诊断等关键任务,提升准确率可能事关生死,可接受使用更昂贵但更精准的模型。而高并发的成本敏感应用则要精打细算,判断性能提升是否值回成本。
其他限制条件:
多语言支持:通用模型往往对非英文内容表现不佳,可能需要多语言专用模型。
专业领域支持:通用模型无法理解特定术语,比如医疗中的 “stat” 或法律中的 “consideration”。需考虑 BioBERT、LegalBERT 等专业模型。
硬件/延迟要求:模型体积和推理速度直接影响部署的可行性。
二、评估数据特性
你的数据特性将直接影响模型选择。需考虑以下几点:
数据模态:文本、图像、音频还是多模态?选用匹配的数据类型模型:
文本:BERT、Sentence-BERT;
图像:CNN 或 Vision Transformer;
多模态:CLIP、MagicLens;
音频:CLAP、PNN 等。
领域特定性:是否需要专用模型?OpenAI 等通用模型对大众话题表现良好,但在医疗、法律等专业场景下可能抓不到细微差别,需考虑 BioBERT 等行业专用模型。
Embedding 类型选择:
稀疏 embedding(如 BM25)擅长关键词匹配;
稠密 embedding(如 BERT)擅长语义理解;
实践中常用混合方案:用稀疏 embedding 做精准匹配,稠密 embedding 做语义召回。
三、调研可用模型
了解任务与数据后,开始调研候选模型:
受欢迎程度:选择社区活跃、使用广泛的模型更有保障,易于排障、更新快、文档丰富。
文本:OpenAI embeddings、Sentence-BERT、E5/BGE;
图像:ViT、ResNet,文本图像对齐可用 CLIP、SigLIP;
音频:PNN、CLAP 等。
版权与许可:
开源模型(MIT、Apache 2.0)适合自建部署,灵活性高但需运维能力;
第三方 API 模型部署简单但费用持续、存在数据隐私和合规性顾虑;
特别是金融、医疗等行业,自托管部署可能是唯一选择。
四、评估候选模型
初步筛选后,需在真实数据上测试模型质量:
质量评估:
对于语义检索、RAG 应用,重点关注:结果的真实性(faithfulness)、相关性(relevance)、上下文精度和召回率。
可借助工具如 Ragas、DeepEval、Phoenix、TruLens-Eval,统一评估流程。
数据集选择也很重要,可基于真实案例、用 LLM 合成、或使用工具(如 Ragas、FiddleCube)构造。
基准测试:
可参考公开 benchmark,如 MTEB(用于语义检索)。
注意不同场景排名差异大,通用 benchmark 表现佳不代表真实环境中也优。
应用自己的样本测试,防止模型对 benchmark 过拟合、在实际数据上反而不如人意。
负载测试:
自部署模型时,需模拟真实并发请求,测试 GPU 利用率、内存占用、吞吐和延迟。
有些模型单机测试效果不错,但在高负载下资源消耗过大,影响上线。
一般来说,比较常见的基准测试榜单有以下几种:
(1)文本数据:MTEB 排行榜
HuggingFace 的 MTEB leaderboard 是一个一站式的文本 Embedding 模型榜,我们可以了解每个模型的平均性能。
可以将“Retrieval Average”列进行降序排序,因为这最符合向量搜索的任务。然后,寻找排名最高、占内存最小的模型。
Embedding 向量维度是向量的长度,即 f(x)=y 中的 y,模型将输出此结果。
最大 Token 数是输入文本块的长度,即 f(x)=y 中的 x ,您可以输入到模型中。
除了通过 Retrieval 任务排序外,还可以根据以下条件进行过滤:
语言:支持法语、英语、中文、波兰语。(例如:task=retrieval, Language=chinese)。
法律领域文本。(例如:task=retrieval,Language=law)
(2)图像数据:ResNet50
有时候我们可能想要搜索与输入图像相似的图片。比如,当我们想寻找更多苏格兰折耳猫的图片。在这种情况下,您可以上传一张苏格兰折耳猫的图片,并要求搜索引擎找到类似的图片。
ResNet50 是一种流行的 CNN 模型,最初由微软在 2015 年使用 ImageNet 数据训练。
同样,对于视频搜索,ResNet50 仍然可以将视频转换为 Embedding 向量。然后,对静态视频帧进行相似性搜索,返回给用户最相似的视频作为最匹配结果。
(3)音频数据:PANNs
类似于以图搜图,也可以基于输入的音频片段搜索相似音频。
PANNs(预训练音频神经网络)是常用的音频搜索 Embedding 模型,因为 PANNs 基于大规模音频数据集预训练,并且擅长音频分类和标记等任务。
(4)多模态图像与文本数据:SigLIP
近几年,涌现了一批针对多种非结构化数据(文本、图像、音频或视频)混合训练的 Embedding 模型。这些模型能够在同一向量空间内同时捕获多种类型的非结构化数据的语义。
多模态 Embedding 模型支持使用文本搜索图像、为图像生成文本描述或以图搜图。
OpenAI 在 2021 年推出的 CLIP 是标准的 Embedding 模型。但由于其需要用户自行进行微调,并不好用,所以到了 2024 年,谷歌推出了的 SigLIP(Sigmoidal-CLIP)。该模型在使用 zero-shot prompt时取得了不错的表现。
(5)多模态文本、音频、视频数据
多模态文本-音频 RAG 系统大多使用多模态生成型 LLM。这类应用首先将声音转换为文本,生成声音-文本对,然后将文本转换为 Embedding 向量。之后我们可以像往常一样使用 RAG 来检索文本。在最后一步,文本被映射回音频。
OpenAI 的 Whisper 可以将语音转录为文本。此外,OpenAI 的 Text-to-speech (TTS) 模型也可以将文本转换成音频。
多模态文本-视频的 RAG 系统使用类似的方法首先将视频映射到文本,转换为 Embedding 向量,搜索文本,并返回视频作为搜索结果。
OpenAI 的 Sora 可以将文本转换成视频。与 Dall-e 类似,您提供文本提示,而 LLM 生成视频。Sora 还可以通过静态图像或其他视频生成视频。
五、集成部署规划
选定模型后,考虑集成策略:
权重选择:直接使用预训练权重上手快,但若需领域定制化,需投入资源微调。微调虽能提升效果,但需评估其投入产出比。
部署方式选择:
自托管:控制力强、可降低大规模使用成本,数据私密性好,但需运维能力;
云服务 API:部署快、运维省心,但存在网络延迟、成本累积问题。
系统集成设计:
包括 API 设计、缓存策略、批处理方案;
选择合适的向量数据库存储与检索 embedding,如 Milvus、Faiss 等。
六、端到端测试
在生产上线前,务必进行闭环测试:
性能验证:
用实际业务数据验证是否符合预期;
检查检索相关指标(MRR、MAP、NDCG),准确率指标(Precision、Recall、F1),以及运行效率(吞吐、P95/P99 延迟)。
鲁棒性测试:
- 模拟不同输入情况,确保模型能稳定应对边缘情况与复杂数据。
如有必要,我们可以可以在自己的数据集上评估Embedding模型。以下是一个Embedding模型的流程示例:
数据集准备如下:
| Language | Description |
|---|---|
| C/C++ | A general-purpose programming language known for its performance and efficiency. It provides low-level memory manipulation capabilities and is widely used in system/software development, game development, and applications requiring high performance. |
| Java | A versatile, object-oriented programming language designed to have as few implementation dependencies as possible. It is widely used for building enterprise-scale applications, mobile applications (especially Android), and web applications due to its portability and robustness. |
| Python | A high-level, interpreted programming language known for its readability and simplicity. It supports multiple programming paradigms and is widely used in web development, data analysis, artificial intelligence, scientific computing, and automation. |
| JavaScript | A high-level, dynamic programming language primarily used for creating interactive and dynamic content on the web. It is an essential technology for front-end web development and is increasingly used on the server-side with environments like Node.js. |
| C# | A modern, object-oriented programming language developed by Microsoft. It is used for developing a wide range of applications, including web, desktop, mobile, and games, particularly within the Microsoft ecosystem. |
| SQL | A domain-specific language used in programming and managing relational databases. It is essential for querying, updating, and managing data in databases, and is widely used in data analysis and business intelligence. |
| PHP | A server-side scripting language designed primarily for web development. It is embedded into HTML and is widely used for building dynamic web pages and applications, with a strong presence in content management systems like WordPress. |
| Golang | A statically typed, compiled programming language designed by Google. Known for its simplicity and efficiency, it is used for building scalable and high-performance applications, particularly in cloud services and distributed systems. |
| Rust | A systems programming language focused on safety and concurrency. It provides memory safety without using a garbage collector and is used for building reliable and efficient software, particularly in systems programming and web assembly. |
接下来,我们采用pymilvus[model]对于上述数据集生成相应的向量Embedding。
def gen_embedding(model_name):
openai_ef = model.dense.OpenAIEmbeddingFunction(
model_name=model_name,
api_key=os.environ["OPENAI_API_KEY"]
)
docs_embeddings = openai_ef.encode_documents(df['description'].tolist())
return docs_embeddings, openai_ef
然后,把生成的Embedding存入到Milvus 的collection。
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
查询
我们定义查询函数,方便对于向量Embedding进行召回。
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
评估Embedding模型性能
我们采用 OpenAI的两个 Embedding模型,text-embedding-3-small 和 text-embedding-3-large,对于如下两个查询进行比较。有很多评估指标,例如准确率、召回率、MRR、MAP等。在这里,我们采用准确率和召回率。
准确率(Precision) 评估检索结果中的真正相关内容的占比,即返回的结果中有多少与搜索查询相关。
Precision = TP / (TP + FP)
其中,检索结果中与查询真正相关的内容 True Positives(TP), 而 False Positives(FP) 指的是检索结果中不相关的内容。
召回率 (Recall)评估从整个数据集中成功检索到相关内容的数量。
Recall = TP / (TP + FN)
其中,False Negatives (FN) 指的是所有未包含在最终结果集中的相关项目
对于这两个概念更详细的解释,参见 thttps://zilliz.com/learn/information-retrieval-metrics
查询 1:auto garbage collection
相关项: Java, Python, JavaScript, Golang
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ❎ Rust | ❎ Rust |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Precision | 0.50 | 0.50 |
| Recall | 0.50 | 0.50 |
查询 2: suite for web backend server development
相关项: Java, JavaScript, PHP, Python (答案包含主观判断)
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Precision | 0.75 | 1.0 |
| Recall | 0.75 | 1.0 |
在这两个查询中,我们通过准确率和召回率对比了两个Embedding模型 text-embedding-3-small 和 text-embedding-3-large 。我们可以以此为起点,增加数据集中数据对象的数量以及查询的数量,如此才能更有效地评估Embedding模型。
总结
选型的关键是遵循以下六步:
明确业务目标与任务类型
分析数据特性与领域需求
调研现有模型与授权模式
用测试集和 benchmark 严格评估
设计部署与集成方案
进行全链路上线前测试
要记住,最合适的模型不一定是 benchmark 分最高的,而是最契合你业务实际需求与技术约束的模型。
在 embedding 模型快速迭代的时代,也建议大家可以定期复盘已有选型,持续关注新的模型与技术,及时替换可能带来重大收益的解决方案。
 王舒虹
王舒虹


